Agent conversationnel avancé : RAG, tool-calling et métriques
Intelligence artificielle
Stratégie IA
Outils IA
Conception conversationnelle
Un chatbot « qui répond bien » n’est plus un avantage concurrentiel. En 2026, la différence se fait sur la capacité à **brancher l’IA à vos sources de vérité (RAG)**, à **déclencher des actions réelles (tool-calling)**, puis à **prouver l’impact avec des métriques fiables**. C’est ce triptyque qui t...
mars 09, 2026·10 min de lecture
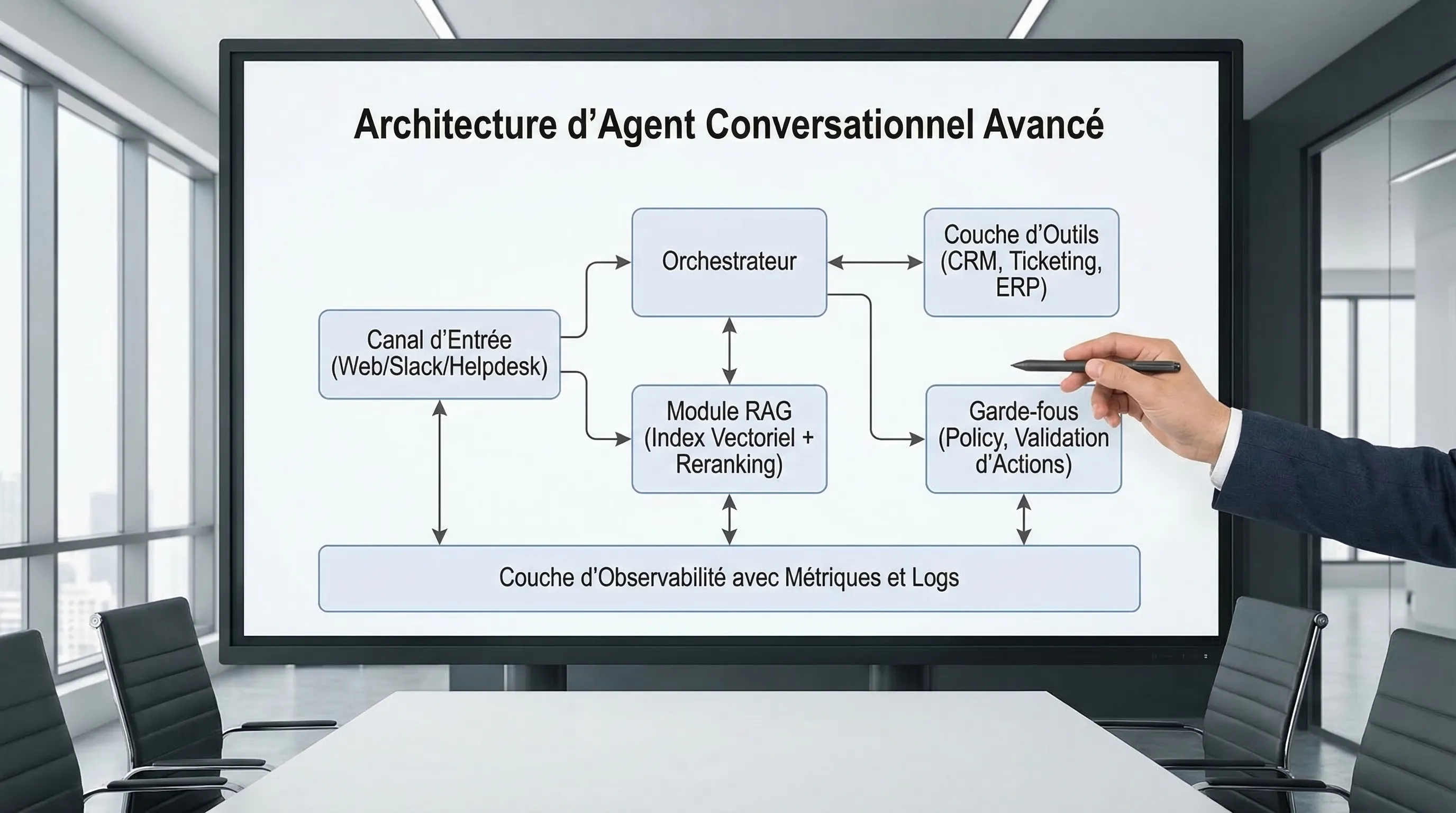
Un chatbot « qui répond bien » n’est plus un avantage concurrentiel. En 2026, la différence se fait sur la capacité à brancher l’IA à vos sources de vérité (RAG), à déclencher des actions réelles (tool-calling), puis à prouver l’impact avec des métriques fiables. C’est ce triptyque qui transforme un simple chat en agent conversationnel avancé utilisable en production, sur un site, dans un helpdesk, ou dans un outil interne.
L’objectif de cet article est pragmatique : vous donner une architecture de référence, les points de design qui évitent les « démos magiques », et un cadre de mesure pour piloter la qualité, les coûts et le ROI.
Ce qu’on appelle vraiment un « agent conversationnel avancé »
Un agent conversationnel avancé n’est pas seulement un modèle plus puissant. C’est un système qui :
comprend une intention (question, tâche, demande d’action),
s’ancre dans un contexte vérifiable (documents, CRM, helpdesk, base de connaissances),
agit via des outils (créer un ticket, chercher une commande, planifier un RDV),
rend des comptes (logs, sources, métriques, garde-fous).
Si vous voulez une définition plus « système », vous pouvez aussi partir de la notion d’agent IA (perception, décision, action) et l’appliquer au conversationnel.
La plupart des échecs viennent d’un mauvais cadrage : on attend d’un chat qu’il fasse tout, partout, pour tout le monde. Un agent robuste a, au contraire, un contrat explicite : périmètre, sources autorisées, actions permises, critères d’échec, escalade humaine.
RAG : la brique qui transforme le chat en système fiable
Le RAG répond à un besoin simple : un LLM est fort pour formuler et raisonner, mais il n’est pas votre base de connaissances. Le RAG sert à raccrocher la réponse à une source de vérité.
Les 4 décisions RAG qui changent vos résultats
1) Quelles sources, pour quelles questions
Un agent conversationnel avancé doit séparer :
contenu « politique » (CGV, process, règles internes),
contenu « produit » (docs, FAQ, specs),
contenu « cas client » (tickets, échanges, incidents),
données transactionnelles (commandes, factures, statut de livraison).
Les deux dernières catégories nécessitent souvent des contrôles d’accès plus stricts, et parfois un passage par tool-calling plutôt que par RAG (exemple : « où en est ma commande ? »).
2) Chunking et qualité documentaire
Un RAG moyen sur de mauvais documents reste un RAG moyen. Les points pratiques qui reviennent :
documents à jour, versionnés, avec owners,
structure (titres, sections),
suppression des doublons et pages « mortes »,
règles de nommage, et métadonnées utiles (produit, pays, date, confidentialité).
3) Retrieval, reranking, et « question rewriting »
En production, la qualité est rarement « un seul vecteur store et basta ». Les gains viennent de petites améliorations :
réécriture de requête (reformuler la question pour mieux chercher),
filtres par métadonnées (ex. langue, produit, segment client),
reranking (réordonner les passages retrouvés pour maximiser la pertinence),
citations (liens vers passages, titres, sources).
Si vous voulez aller plus loin sur l’industrialisation, vous pouvez compléter avec l’article Impulse Lab sur un RAG robuste en production.
4) Mémoire conversationnelle : utile, mais dangereuse sans contrat
Beaucoup de produits ajoutent une « mémoire » trop tôt. Pour un agent avancé, posez d’abord :
Qu’est-ce qui doit être mémorisé ? (préférences, contexte de compte, historique de ticket)
Combien de temps ? (session, 30 jours, 1 an)
Qui peut le voir ? (support, admin, utilisateur)
Comment l’utilisateur la corrige ou la supprime ?
Sans ces réponses, vous créez des erreurs difficiles à diagnostiquer et des risques RGPD inutiles.
Tool-calling : passer de « je réponds » à « je fais »
Le tool-calling (function calling, tool use) désigne la capacité du modèle à déclencher une action structurée : appeler une API, lire un système, créer ou mettre à jour un objet (ticket, lead, commande). Les éditeurs documentent largement ces mécanismes, par exemple côté OpenAI (Function Calling) et côté Anthropic (Tool use).
Les 3 patterns d’action les plus rentables en PME et scale-up
Pattern 1 : « Lookup » (lecture)
L’agent interroge un système puis répond.
Exemples : statut de commande, SLA, dernière facture, disponibilité d’un créneau.
Pattern 2 : « Create/Update » (écriture) avec prévisualisation
L’agent prépare une action, puis demande confirmation.
Exemples : créer un ticket pré-rempli, enregistrer un lead qualifié, générer un devis brouillon.
Pourquoi c’est critique : c’est là que les agents deviennent dangereux si vous n’imposez pas une étape de validation.
Pattern 3 : « Orchestration » (multi-outils) à autonomie limitée
L’agent enchaîne plusieurs étapes, mais reste encadré.
Exemples : qualifier une demande, vérifier l’éligibilité, créer le ticket, notifier Slack, mettre à jour le CRM.
Garde-fous indispensables pour le tool-calling
Le tool-calling n’est pas une « feature », c’est une surface de risque. Les garde-fous minimaux :
Scopes et permissions : un agent n’a accès qu’aux APIs et aux objets nécessaires.
Validation explicite : pour toute action qui a un impact client, financier, ou légal.
Idempotence : un retry ne doit pas créer deux tickets.
Journalisation : conserver la décision, les paramètres, le résultat, et l’identité.
Détection d’injection : une partie de la sécurité est liée à la prompt injection, documentée dans des ressources comme l’OWASP Top 10 for LLM Applications.
Les métriques : le vrai critère « avancé » en production
Un agent conversationnel avancé se pilote comme un produit : on ne mesure pas seulement « est-ce que ça marche », on mesure combien ça rapporte, à quel coût, et avec quel niveau de risque.
Pour éviter la confusion, utilisez une structure en 4 couches (très utilisée en environnement produit) :
Impact business (ROI)
Performance process (opérations)
Expérience utilisateur (adoption et satisfaction)
Qualité technique et IA (fiabilité, coût, latence)
Tableau de bord minimal (à tenir chaque semaine)
Couche
Métrique
Ce que ça prouve
Exemple d’alerte
Business
Taux de déflexion (support) ou RDV qualifiés (sales)
Création de valeur
Déflexion monte, mais CSAT baisse
Process
Temps moyen de résolution (ou temps de première réponse)
Gain opérationnel
Réponses plus rapides, mais plus d’escalades
Expérience
Taux de complétion (objectif atteint sans humain)
Utilité réelle
Beaucoup de conversations, peu d’objectifs atteints
IA/Tech
Taux de réponses « sans source » en RAG
Robustesse
Le modèle répond sans preuve sur des sujets sensibles
Les métriques RAG à suivre (sinon vous pilotez à l’aveugle)
Sans tomber dans la sur-ingénierie, trois familles de signaux sont très actionnables :
Qualité de récupération : la source est-elle pertinente, ou hors sujet ?
Ancrage : la réponse est-elle supportée par les passages cités ?
Couverture : combien de questions tombent « hors base » (et doivent basculer vers humain ou vers un autre système) ?
En pratique, vous aurez aussi besoin d’un golden set : un pack de questions représentatives, avec réponses attendues et sources de référence, pour tester hors-ligne avant chaque évolution.
Évaluer et améliorer : offline, pilote, production
Le piège classique est de tester « à la main » pendant une semaine, puis de conclure. Pour un agent conversationnel avancé, adoptez un protocole par niveaux.
Niveau 1 : offline (avant de montrer à des utilisateurs)
pack de scénarios (questions fréquentes, cas limites, données sensibles)
évaluation de la qualité RAG (sources, citations, contradictions)
tests d’outils (tool-calling) en environnement sandbox
Niveau 2 : pilote contrôlé (petit volume, vrais utilisateurs)
périmètre limité (un segment client, un produit, un canal)
escalade humaine systématique si incertitude
instrumentation dès le jour 1 (événements, coûts, erreurs)
Niveau 3 : production progressive
rollout par paliers (10 %, puis 30 %, puis 100 %)
monitoring continu (qualité, coûts, incidents)
runbook : qui fait quoi quand le système se dégrade
Sur la gouvernance de l’IA, des cadres comme le NIST AI RMF aident à structurer risques, contrôles et responsabilités, sans transformer votre projet en usine à gaz.
Sécurité, conformité et confiance : les non-négociables
Un agent conversationnel avancé manipule des données et peut déclencher des actions, donc il doit être conçu comme un système sensible.
Les points qui reviennent le plus souvent en PME et scale-up :
Minimisation des données : ne pas envoyer plus que nécessaire au modèle.
Gestion des identités : savoir qui parle, et quels droits appliquer.
Séparation des environnements : sandbox pour les actions, production pour le réel.
Logs exploitables : conserver suffisamment pour auditer, sans stocker inutilement.
Politique d’escalade : quand le chat passe la main, et comment.
Côté RGPD, le plus efficace est d’éviter les débats théoriques et de partir d’un inventaire simple : quelles données, pour quelle finalité, quelle durée, quels sous-traitants, quels contrôles.
Plan de déploiement réaliste (30 jours) pour une V1 mesurable
Plutôt que de viser un « agent universel », un plan rapide et rationnel consiste à livrer une V1 étroite mais instrumentée.
1 métrique North Star (ex. tickets évités, RDV qualifiés, temps gagné)
le contrat d’agent (périmètre, sources, actions, échecs, escalade)
Semaine 2 : RAG utile, pas « parfait »
sélection des sources à forte valeur
indexation et métadonnées minimales
citations obligatoires sur les sujets sensibles
Semaine 3 : tool-calling sur un flux simple
1 ou 2 outils maximum au départ
prévisualisation, confirmation, idempotence
logs et métriques coûts par action
Semaine 4 : pilote + décision
déploiement sur un petit périmètre
revue hebdo des métriques
décision : scaler, corriger, ou arrêter
C’est cette discipline (contrat + intégration + métriques) qui fait passer d’un chatbot « sympa » à un agent conversationnel avancé qui crée de la valeur.
Quand passer au sur-mesure (et quand rester sur un outil)
Vous pouvez souvent démarrer avec un outil du marché si :
le périmètre est simple,
les données ne sont pas sensibles,
les intégrations sont standard,
la mesure est possible.
Le sur-mesure devient pertinent quand :
vous avez des intégrations spécifiques (ERP, outils internes),
vous voulez maîtriser la qualité et le coût en production.
Impulse Lab accompagne justement ce type de trajectoire, via des audits d’opportunités IA, de la formation à l’adoption, et le développement de solutions web et IA sur mesure, intégrées à vos outils existants. Si vous voulez, on peut cadrer ensemble un cas d’usage « agent-ready » et définir la V1 mesurable à livrer en quelques semaines.