Agents autonomes en entreprise : garde-fous et validation
Intelligence artificielle
Stratégie IA
Validation IA
Gestion des risques IA
Automatisation
Les agents autonomes en entreprise promettent un saut de productivité, car ils ne se contentent pas de “répondre” mais **planifient et exécutent** des actions dans vos outils (CRM, ERP, helpdesk, messagerie, bases documentaires). Le problème est simple : plus l’agent agit, plus l’erreur coûte cher....
Les agents autonomes en entreprise promettent un saut de productivité, car ils ne se contentent pas de “répondre” mais planifient et exécutent des actions dans vos outils (CRM, ERP, helpdesk, messagerie, bases documentaires). Le problème est simple : plus l’agent agit, plus l’erreur coûte cher. Sans garde-fous et sans validation structurée, vous passez vite d’un gain de temps à un incident (données exposées, actions irréversibles, dérives de coûts, décisions non conformes).
L’objectif de cet article est pragmatique : vous donner un cadre de garde-fous (sécurité, conformité, fiabilité, coût) et un process de validation pour mettre des agents en production sans “ralentir” l’organisation.
Ce qui change avec un agent autonome (et pourquoi les garde-fous sont non négociables)
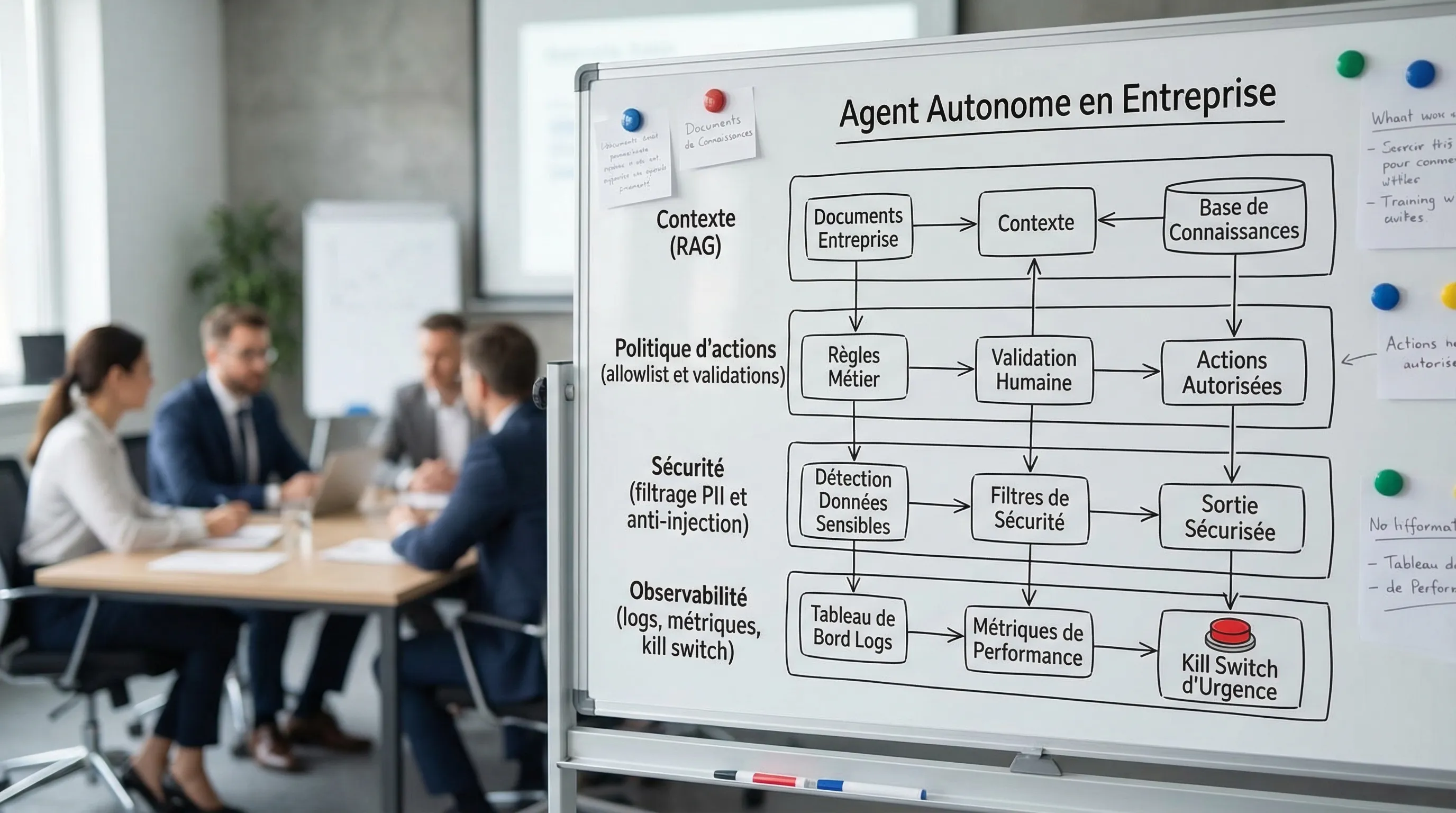
Un agent autonome n’est pas juste un chatbot. Il combine généralement :
un modèle (souvent un LLM) pour raisonner et générer,
un contexte (RAG, mémoire, outils internes),
des “tools” ou actions (API, automatisations, écriture en base, envoi d’emails),
une boucle de décision (planifier, exécuter, vérifier).
Cette boucle introduit trois risques récurrents :
Le risque d’action : l’agent fait “quelque chose”, parfois irréversible (suppression, envoi, création de ticket, changement de statut, modification de prix).
Le risque d’information : l’agent affirme une information fausse, ou récupère des données non pertinentes, ou fuit des données (prompt injection, mauvaise ACL, documents sensibles).
Le risque d’exploitation : coût d’inférence qui explose, latence, erreurs silencieuses, absence de traçabilité, difficulté à reproduire et corriger.
Étape 0 : écrire le “contrat d’agent” avant de brancher des outils
Avant même de parler de garde-fous techniques, formalisez un contrat d’agent. C’est un document court, mais il évite 80% des dérives.
Les 6 clauses minimales d’un contrat d’agent
Objectif : quel résultat métier et quel KPI (temps de traitement, taux de résolution, taux de conversion, réduction d’erreurs).
Périmètre : ce que l’agent traite, et ce qu’il ne traite jamais (ex : “pas de résiliation”, “pas de remboursement”, “pas de décision de crédit”).
Sources de vérité : quelles données il a le droit d’utiliser (et sous quelles règles d’accès).
Actions autorisées : liste explicite, avec niveau d’autonomie (proposer, exécuter avec validation, exécuter seul).
Critères d’échec : ce qui déclenche escalade humaine (incertitude, ambiguïté, données manquantes, intention suspecte).
Traçabilité : ce qu’on journalise (inputs, documents consultés, actions proposées/exécutées, identifiant de version).
Si vous avez besoin d’une base, vous pouvez vous appuyer sur une définition claire de ce qu’est un agent via le lexique Impulse Lab : agent IA.
Les garde-fous essentiels (par couche) : contexte, action, sécurité, coûts
Un bon design d’agent, en entreprise, ressemble moins à “un prompt” qu’à un système avec portes, limites et preuves.
1) Garde-fous sur le contexte (RAG, outils, mémoire)
Quand un agent se trompe, c’est souvent parce que le contexte est mauvais (documents non à jour, chunking incohérent, permissions mal gérées, ou sources contradictoires). Les garde-fous utiles :
Sources vérifiables : privilégier des réponses “avec preuves” (citations, liens internes, extraits) plutôt que des réponses “fluent mais invérifiable”.
Contrôle d’accès au niveau document : l’agent ne doit jamais pouvoir récupérer un document que l’utilisateur n’a pas le droit de voir.
Versionnage de la base de connaissance : vous devez savoir quel corpus a été consulté, surtout si votre documentation bouge.
Détection d’instructions malveillantes : la prompt injection vise souvent à détourner l’agent via des contenus récupérés. Le cadre OWASP cité plus haut est un bon point de départ.
2) Garde-fous sur l’action (c’est là que tout se joue)
En entreprise, les actions doivent être conçues comme des “API sûres”, pas comme des pouvoirs magiques.
Les patterns les plus robustes :
Allowlist d’actions : l’agent n’a accès qu’à une liste fermée de fonctions. Pas d’accès “générique” à une API.
Prévisualisation : avant exécution, l’agent affiche un brouillon (email, ticket, mise à jour CRM) avec un bouton “valider”.
Idempotence : si l’agent répète une action (latence, retry), l’effet doit rester unique (par exemple via un idempotency key).
Double validation sur actions sensibles : certains gestes nécessitent un deuxième “OK” ou un rôle spécifique.
Garde-fou métier : règles déterministes au-dessus du LLM (ex : “ne jamais envoyer à un domaine externe”, “ne jamais modifier le prix”, “ne jamais agir sans champ obligatoire”).
C’est souvent la couche la plus rentable : même si le modèle hallucine, vous empêchez l’erreur d’atterrir dans vos systèmes.
3) Garde-fous sécurité, données et conformité (RGPD, AI Act)
Sans rentrer dans le juridique au mot près, une posture saine consiste à traiter l’agent comme un système qui manipule des données potentiellement sensibles.
Contrôles typiques :
Classification des données (public, interne, sensible) et interdiction d’envoyer certaines classes vers des services non autorisés.
Minimisation : envoyer le minimum nécessaire au modèle (pseudonymisation quand c’est possible).
Journalisation et audit : qui a demandé quoi, quelles sources ont été consultées, quelle action a été exécutée.
Contrat fournisseur et règles de rétention : DPA, options “no training”, localisation, durées.
Pour la conformité, gardez un œil sur le cadre européen, notamment l’EU AI Act (Commission européenne) qui structure les obligations selon le niveau de risque, et sur les recommandations opérationnelles de la CNIL sur l’IA.
Golden set, réévaluation continue, versioning prompts/corpus
Score qualité, taux de correction humaine
Dérive de coûts
Facture qui double en 2 semaines
Budgets, cache, limites de contexte, routage modèles
Coût/run, tokens/run, latence/run
Validation : un protocole en 3 niveaux (offline, pilote, production)
Valider un agent autonome n’est pas “le tester une fois”. C’est un cycle : prouver qu’il fonctionne, prouver qu’il est safe, puis le surveiller.
Niveau 1 : validation offline (avant tout accès réel)
Objectif : casser l’agent en environnement contrôlé.
Pack de scénarios : cas normaux, cas limites, cas malveillants (injection, demandes hors périmètre, manque de données).
Golden set : un jeu de tests stable pour comparer les versions (prompts, modèles, RAG, outils).
Tests d’action simulée : l’agent “propose” l’action, mais ne l’exécute jamais.
Si vous cherchez une méthode reproductible, la logique “protocole de test + scorecard go/no-go” est détaillée dans l’esprit des approches de validation en entreprise (voir aussi l’article Impulse Lab sur le testing IA : Enterprise AI testing).
Niveau 2 : pilote contrôlé (avec de vrais utilisateurs, mais des barrières)
Objectif : mesurer la valeur et les risques en conditions réelles, sans dégâts.
HITL (human-in-the-loop) : l’agent propose, l’humain valide, puis exécution.
Périmètre réduit : une équipe, un type de demande, un canal.
Industrialisation seulement après scorecard claire (valeur + risques + exploitation).
Impulse Lab accompagne ce type de démarche via des audits IA, de la formation à l’adoption, et le développement de solutions sur mesure intégrées à vos outils. Si vous voulez, on peut cadrer ensemble un cas d’usage et définir une validation “go/no-go” en quelques jours, avant d’investir plus lourdement.
En PME, l’automatisation est souvent abordée trop tard, quand les équipes passent déjà trop de temps à recopier des données, relancer des dossiers, consolider des fichiers ou vérifier des informations entre plusieurs outils. La **RPA informatique** répond précisément à ce problème : elle permet d’au...