Autonomous agents en entreprise : guide pour passer en production
Intelligence artificielle
Stratégie IA
Gouvernance IA
Gestion des risques IA
Automatisation
Un agent autonome peut très bien impressionner en démo et pourtant échouer dès qu’il doit agir sur des outils réels, avec des données sensibles, sous contrainte de coût et de conformité. Passer en production ne consiste donc pas à “brancher un meilleur modèle”, mais à **transformer un prototype (sou...
Un agent autonome peut très bien impressionner en démo et pourtant échouer dès qu’il doit agir sur des outils réels, avec des données sensibles, sous contrainte de coût et de conformité. Passer en production ne consiste donc pas à “brancher un meilleur modèle”, mais à transformer un prototype (souvent conversationnel) en un système opérable, mesurable, auditable et réversible.
Ce guide s’adresse aux PME, scale-ups et équipes qui structurent leur stack. Objectif, vous donner un chemin clair pour mettre des autonomous agents (agents autonomes) en production sans créer un nouveau risque opérationnel.
Ce que signifie “passer en production” pour un agent
En entreprise, “en production” veut dire que l’agent :
Tourne dans un environnement maîtrisé (identités, secrets, réseau, logs) et pas sur un navigateur personnel.
Exécute des actions traçables (API, tickets, CRM, paiements, emails) avec contrôle d’accès.
A un owner métier et un processus de décision clair (quand on laisse faire, quand on valide, quand on stoppe).
Est évalué en continu (qualité, coûts, taux de réussite) avec des seuils d’alerte.
Dispose d’un mode dégradé (fallback, escalade humaine, “kill switch”).
Le piège classique : confondre “ça répond bien” avec “ça livre un résultat fiable dans un workflow”.
Étape 1, choisir un cas d’usage réellement “agent-ready”
Un agent est pertinent quand il doit enchaîner plusieurs étapes et agir sur des outils, pas quand une simple FAQ ou un RAG suffit.
Les bons signaux
Un cas d’usage est généralement agent-ready si :
La demande est fréquente (plusieurs fois par semaine minimum).
Le résultat est défini et testable (succès/échec observable).
Les actions sont réversibles ou contrôlables (brouillon, prévisualisation, validation).
Les données nécessaires existent dans une source de vérité (CRM, helpdesk, base documentaire).
Les mauvais signaux (à éviter pour une V1)
Objectif flou (“optimiser le support”) sans métrique.
Trop d’exceptions, trop de cas “edge”.
Actions irréversibles dès le départ (annulations, paiements, suppression).
Dépendance à des informations non fiables (documents non maintenus, procédures obsolètes).
Pour une première mise en production, privilégiez des cas comme : triage de tickets, préparation de réponses, enrichissement CRM, génération de devis en brouillon, relances “soft”, reporting hebdo.
Étape 2, écrire le contrat d’agent (document de 1 page)
Le “contrat d’agent” sert à aligner métier, IT et sécurité, et à rendre l’agent testable. Il évite les dérives du type “on verra au fur et à mesure”.
Sources autorisées : documents, bases, APIs (et celles interdites).
Actions autorisées : créer un ticket, rédiger un email, modifier une fiche, etc.
Niveau d’autonomie : suggestion, exécution avec validation, exécution automatique.
Critères d’échec : quand l’agent doit s’arrêter et escalader.
Traçabilité : ce qui doit être loggé (décision, source, action, identité).
KPI : 1 KPI “North Star” + 2 à 4 KPI de pilotage.
Ce document devient la base des tests, des garde-fous et du runbook.
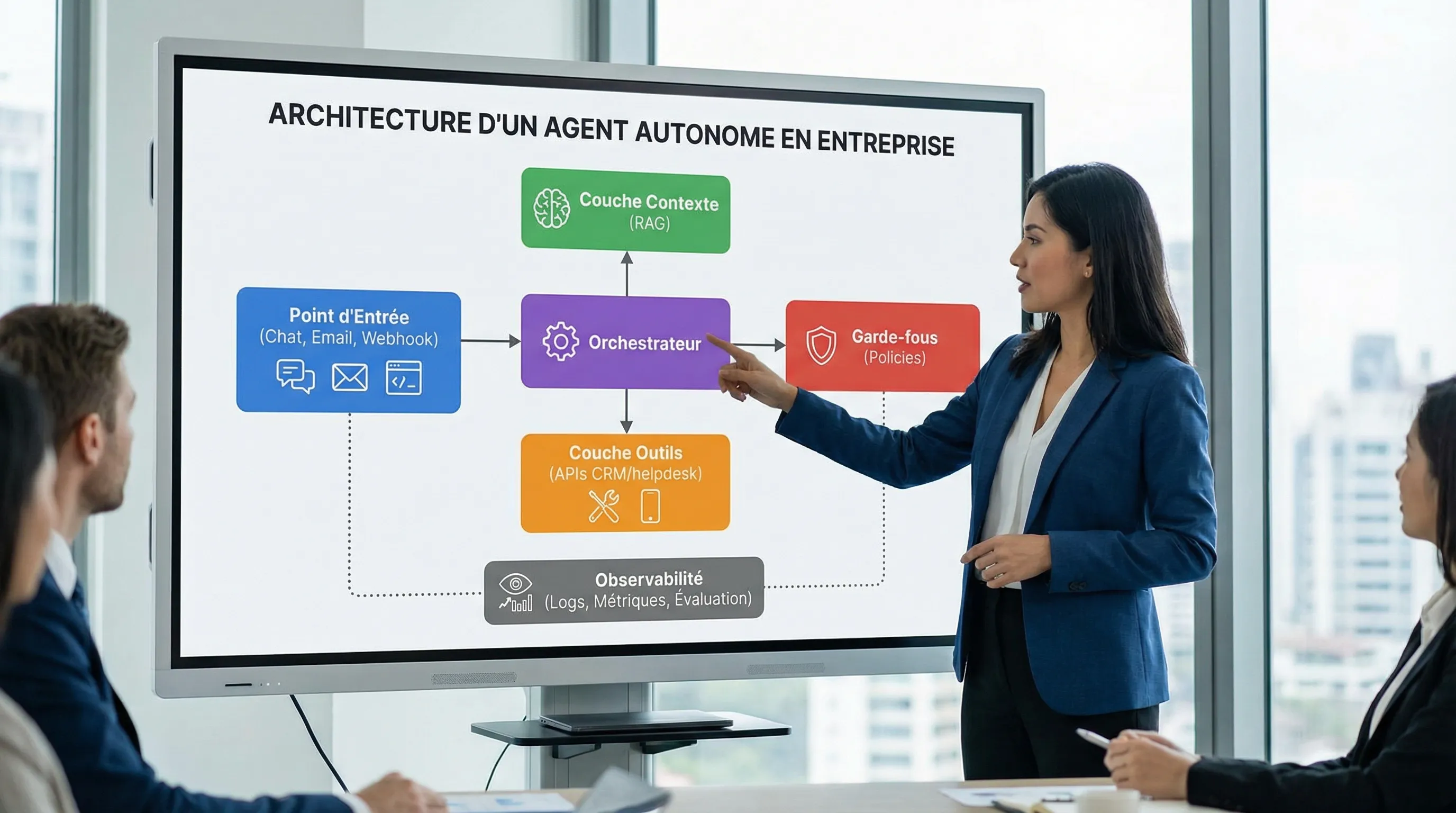
Étape 3, concevoir une architecture minimale “production-grade”
Un agent en production ressemble davantage à un petit produit qu’à une conversation. Vous avez besoin d’une chaîne d’exécution claire, d’un contrôle d’accès et d’un système d’observabilité.
Qui peut déclencher l’agent, et comment authentifier ?
Orchestrateur
Gère état, étapes, retries, timeouts
Où vit l’état, et comment on rejoue proprement ?
Contexte (souvent RAG)
Connecte l’agent à une source de vérité
Quelles sources, quelle fraîcheur, quelles citations ?
Couche outils
Tool-calling vers APIs internes/externes
Quels droits, quelles actions réversibles ?
Garde-fous
Politiques, validations, filtres, limites
Qu’est-ce qui est bloquant, qu’est-ce qui est “review” ?
Observabilité
Logs, métriques, traces, évaluation continue
Que mesure-t-on, et qui regarde ?
Deux décisions “production-first” qui changent tout :
Idempotence : si l’agent rejoue une étape (timeout, retry), il ne doit pas créer deux tickets ou envoyer deux emails.
Prévisualisation : au début, préférez “brouillon + validation” à “envoi direct”.
Intégrations, éviter l’usine à gaz
Vous n’avez pas besoin de connecter 10 outils pour une V1. Une bonne règle : 1 source de vérité + 1 outil d’action.
Si vous devez connecter plusieurs outils, un standard comme le Model Context Protocol (MCP) peut réduire le sur-mesure, mais vous devez quand même traiter la sécurité, les droits et les logs.
Étape 4, sécurité et conformité, traiter l’agent comme un utilisateur “puissant”
Un agent qui agit est une identité opérationnelle. Vous devez donc sécuriser son accès comme vous le feriez pour un compte de service.
Points clés :
Authentification et autorisations
Utilisez des mécanismes robustes d’authentification et limitez les permissions (principe du moindre privilège).
Séparez les rôles : lecture (contexte) vs écriture (actions).
Évitez les clés partagées et gérez les secrets via un coffre.
Journalisation et audit
Loggez : requête, sources consultées, décision, actions, utilisateur demandeur, et identifiants des objets modifiés.
Définissez une politique de rétention des logs compatible RGPD.
RGPD, AI Act, et risk management
Selon votre cas d’usage, vous pouvez être amené à faire une analyse d’impact (DPIA) et à documenter votre gestion des risques.
L’objectif n’est pas de “bureaucratiser”, mais de rendre l’agent proportionné au risque, et défendable en audit.
Étape 5, passer d’une démo à une évaluation reproductible
Un agent doit être évalué comme un système, pas comme une conversation “qui a l’air correcte”. La clé est de bâtir un jeu de tests qui ressemble à la vraie vie.
Construire un “golden set” de scénarios
Constituez 30 à 100 cas représentatifs (tickets, emails, demandes internes), et étiquetez-les :
résultat attendu (succès/échec)
sources à utiliser
action à produire (ou à refuser)
contraintes (données sensibles, escalade)
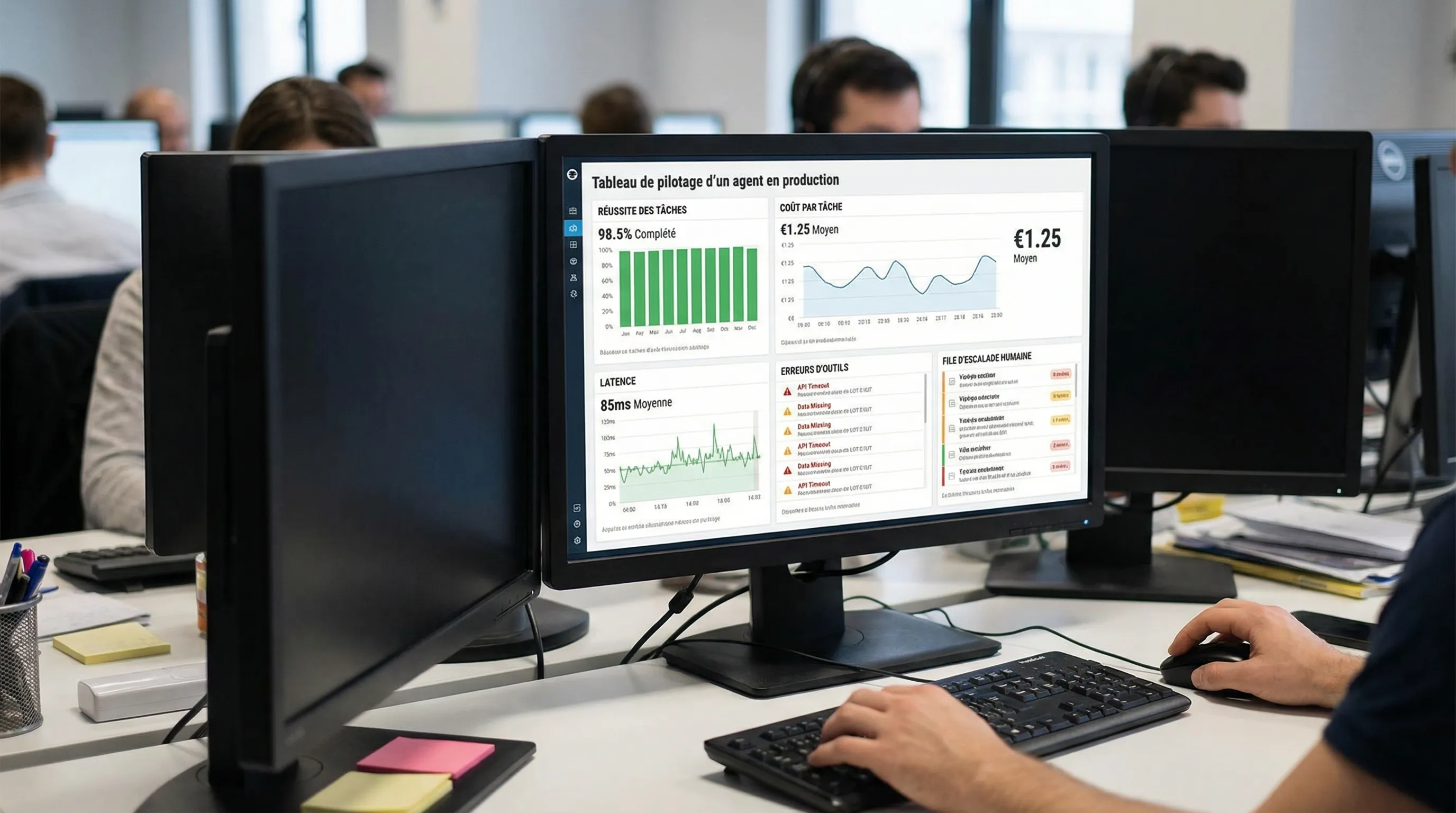
Les métriques minimales à suivre
Catégorie
Métrique utile
Pourquoi c’est important
Efficacité
Taux de tâches réussies (end-to-end)
Mesure la valeur réelle, pas la qualité textuelle
Qualité
Taux de réponses avec sources correctes (si RAG)
Réduit hallucinations et erreurs métier
Sécurité
Taux d’actions bloquées correctement (policy)
Valide vos garde-fous
Coût
Coût moyen par tâche, tokens, appels outils
Évite les surprises de run
Ops
Latence p95, taux d’erreurs tool-calls
Rend l’agent exploitable au quotidien
Conseil : automatisez une partie de l’évaluation (tests offline, tests d’intégration) avant même le pilote, puis gardez un contrôle humain sur les cas critiques.
Étape 6, préparer le runbook, sinon la production vous rattrape
Le runbook est ce qui sépare un “projet IA” d’un service durable. Il doit tenir sur quelques pages et répondre à : que fait-on quand ça se passe mal ?
Un runbook minimal couvre :
SLO/SLA : ce que vous garantissez (latence, disponibilité, taux de réussite).
Incidents : qui est on-call, comment diagnostiquer (logs, traces), comment rollback.
Modes dégradés : passage en “suggestion only”, désactivation d’un outil, escalade.
Kill switch : arrêt immédiat et conditions.
Mise à jour des sources : cadence, owner, procédure.
Gestion des coûts : budgets, rate limit, alerting.
Étape 7, organiser l’adoption, l’agent doit s’insérer dans le travail réel
Même un agent performant échoue si l’équipe ne lui fait pas confiance ou si son output arrive “à côté” du workflow.
Quelques pratiques simples :
Commencez par un mode copilote (brouillons, suggestions) pour construire la confiance.
Ajoutez des éléments d’UX qui réduisent le risque : sources, boutons d’action, confirmations.
Formez par rôle (ops, support, sales), avec des exemples concrets et des règles “do/don’t”.
Si vous structurez votre initiative, une page lexicale comme Agent IA peut aider à aligner le vocabulaire entre équipes.
Un plan réaliste pour une V1 en production (2 à 6 semaines)
Le délai dépend surtout de l’accès aux données, des intégrations et du niveau de risque. Pour une PME ou scale-up, une trajectoire réaliste ressemble à ceci.
Le point clé : vous devez être capable de dire “on coupe” si la V1 n’atteint pas les KPI ou si les coûts explosent. C’est un signe de maturité, pas un échec.
Quand se faire accompagner
Vous gagnerez beaucoup de temps (et éviterez les dettes invisibles) si vous cherchez un partenaire quand :
vous avez plusieurs sources de données, mais aucune “source de vérité” claire,
vous devez connecter l’agent à des outils critiques (CRM, facturation, helpdesk),
la conformité et la sécurité sont non négociables,
vous voulez une V1 en production avec mesure et runbook, pas une démo.
Impulse Lab accompagne ce type de passage en production via des audits d’opportunités, du développement sur mesure, des intégrations avec vos outils, et de la formation à l’adoption. Si vous souhaitez cadrer un agent “agent-ready” et livrer une V1 en cycles courts, vous pouvez démarrer par un échange sur impulselab.ai.