Développement d’agents IA : architecture, tests et runbook
Intelligence artificielle
Stratégie IA
Validation IA
Gouvernance IA
Automatisation
Passer d’une démo d’agent à une capacité fiable en production ne dépend pas du “meilleur modèle”. En 2026, ce qui fait la différence, c’est une **architecture lisible**, une **stratégie de tests reproductible**, et un **runbook d’exploitation** qui anticipe les incidents, les coûts variables et les...
Passer d’une démo d’agent à une capacité fiable en production ne dépend pas du “meilleur modèle”. En 2026, ce qui fait la différence, c’est une architecture lisible, une stratégie de tests reproductible, et un runbook d’exploitation qui anticipe les incidents, les coûts variables et les risques de sécurité.
Cet article propose un cadre concret pour le développement d’agents IA en contexte PME et scale-up, avec des artefacts que vous pouvez réutiliser (architecture de référence, matrice de tests, runbook minimal).
1) Pré-requis: écrire un “contrat d’agent” avant d’architecturer
Avant de parler composants, définissez le contrat. Un agent n’est pas “un chat plus intelligent”, c’est un système qui observe, décide et agit. Sans contrat, votre architecture gonfle, vos tests sont incomplets, et le runbook devient impraticable.
Un contrat d’agent tient sur une page et fixe:
Objectif (KPI métier et définition d’un succès)
Périmètre (ce que l’agent a le droit de traiter, et ce qu’il doit refuser)
Sources de vérité (documents, CRM, ERP, base de tickets)
Actions autorisées (lecture seule, écriture, envoi, création d’objet)
Niveaux d’autonomie (suggestion, exécution avec validation, exécution automatique)
Critères d’échec (quand l’agent doit passer la main, ou stopper)
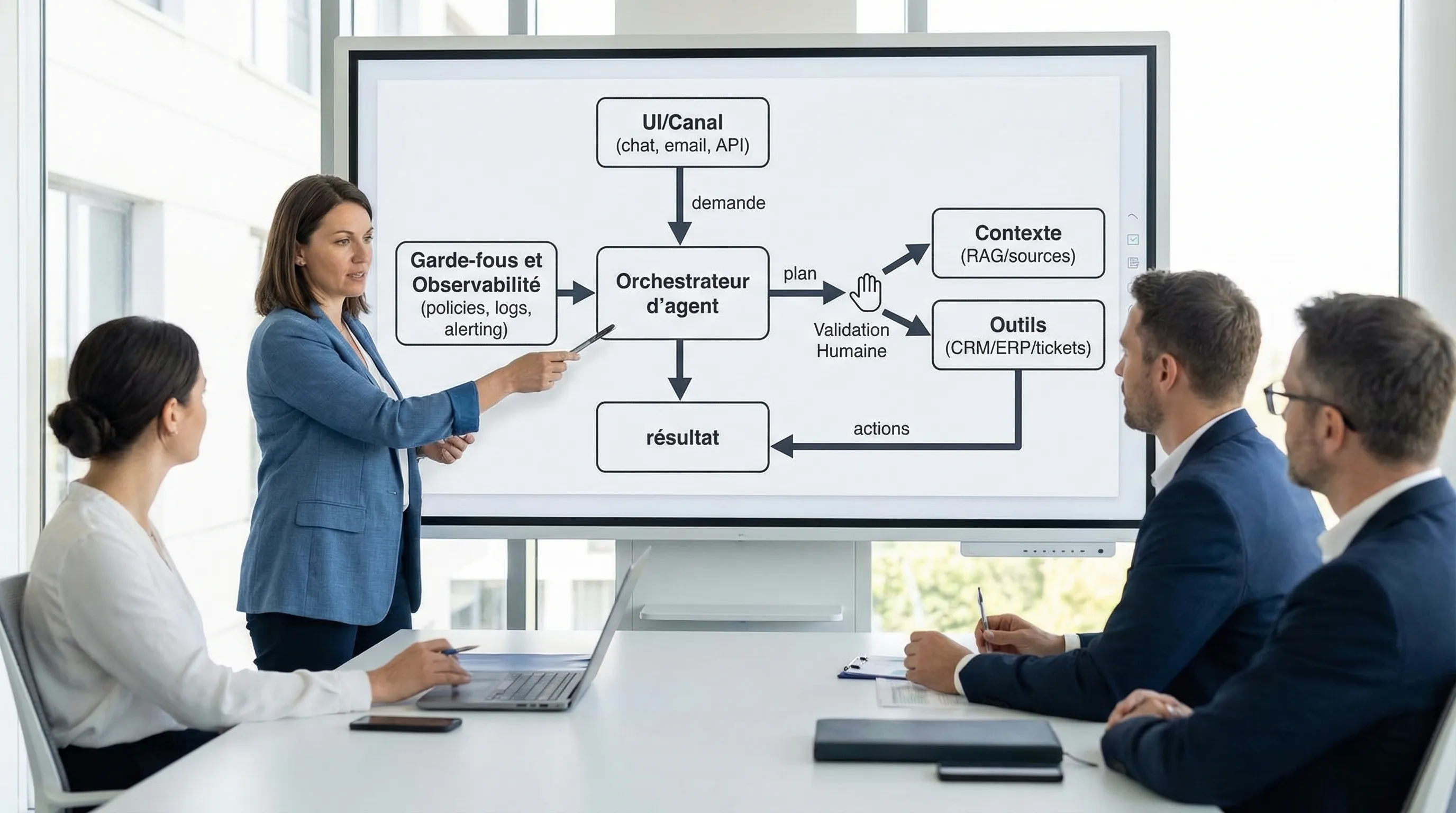
2) Architecture d’agent IA: une référence “production-first”
Une architecture d’agent robuste se pense comme une mini-plateforme: l’agent orchestre, mais les outils, les données et les garde-fous restent séparés. Cela réduit le verrouillage fournisseur, facilite les tests, et évite de coupler votre métier à des prompts.
Les briques essentielles (et ce qu’elles protègent)
Brique
Rôle en production
Risques couverts
Livrable attendu
Canal (UI/API)
Capte l’intention, structure les inputs, gère l’identité
Inputs ambigus, PII, erreurs UX
Contrat d’entrée (schéma), règles de saisie, consentement
Règle 1: séparez “raisonner” et “agir”. L’agent peut proposer un plan, mais l’exécution doit passer par des fonctions outillées avec des contrats stricts (schémas, validations, droits). Cela limite les sorties libres et sécurise les actions.
Règle 2: tout ce qui coûte ou casse doit être mesuré. Tokens, latence, taux d’échec d’outil, taux de “passage humain”, et taux de refus par policy ne sont pas des détails. Ce sont vos futurs incidents.
Intégrations: le point de bascule entre démo et ROI
Dans beaucoup d’organisations, l’agent devient rentable quand il s’intègre à des systèmes “durs” (CRM, helpdesk, ERP) et réduit des frictions récurrentes: qualification, création de tickets, mise à jour d’opportunités, relances, résolution de demandes standard.
Si votre contexte ressemble à une ETI ou une scale-up avec un ERP structurant (par exemple NetSuite), regardez des approches orientées intégration et ROI, comme celles mises en avant par un cabinet de services managés spécialisé en AI et ERP: AI & NetSuite consulting pour le mid-market. L’intérêt ici n’est pas “l’outil”, mais la discipline: cycles courts, intégrations propres, et pilotage du ROI.
3) Stratégie de tests: ce qui est spécifique aux agents (et ce qui ne l’est pas)
Un agent est un système non déterministe, connecté à des outils, exposé à des entrées adverses, et dont le coût varie. Vos tests doivent donc couvrir:
la qualité (réponses correctes et utiles)
la sécurité (injections, fuites, contournements)
la fiabilité d’action (idempotence, permissions, validation)
la performance et le coût (latence, quotas, budgets)
Référence utile côté sécurité: l’initiative OWASP dédiée aux LLM (risques d’injection, fuite de données, abus d’outils) est un bon point de départ pour structurer vos scénarios de test.
Une matrice simple: tests offline, pilote, production
Niveau
Objectif
Ce que vous testez
Artefacts
Offline (pré-prod)
Éviter les régressions et les erreurs évidentes
Prompts/versioning, RAG, outils mockés, règles, cas limites
Golden set, mocks, snapshots, scorecard
Pilote contrôlé
Valider en conditions réelles sans risque
Journaux, taux de handoff, qualité perçue, incidents, coûts
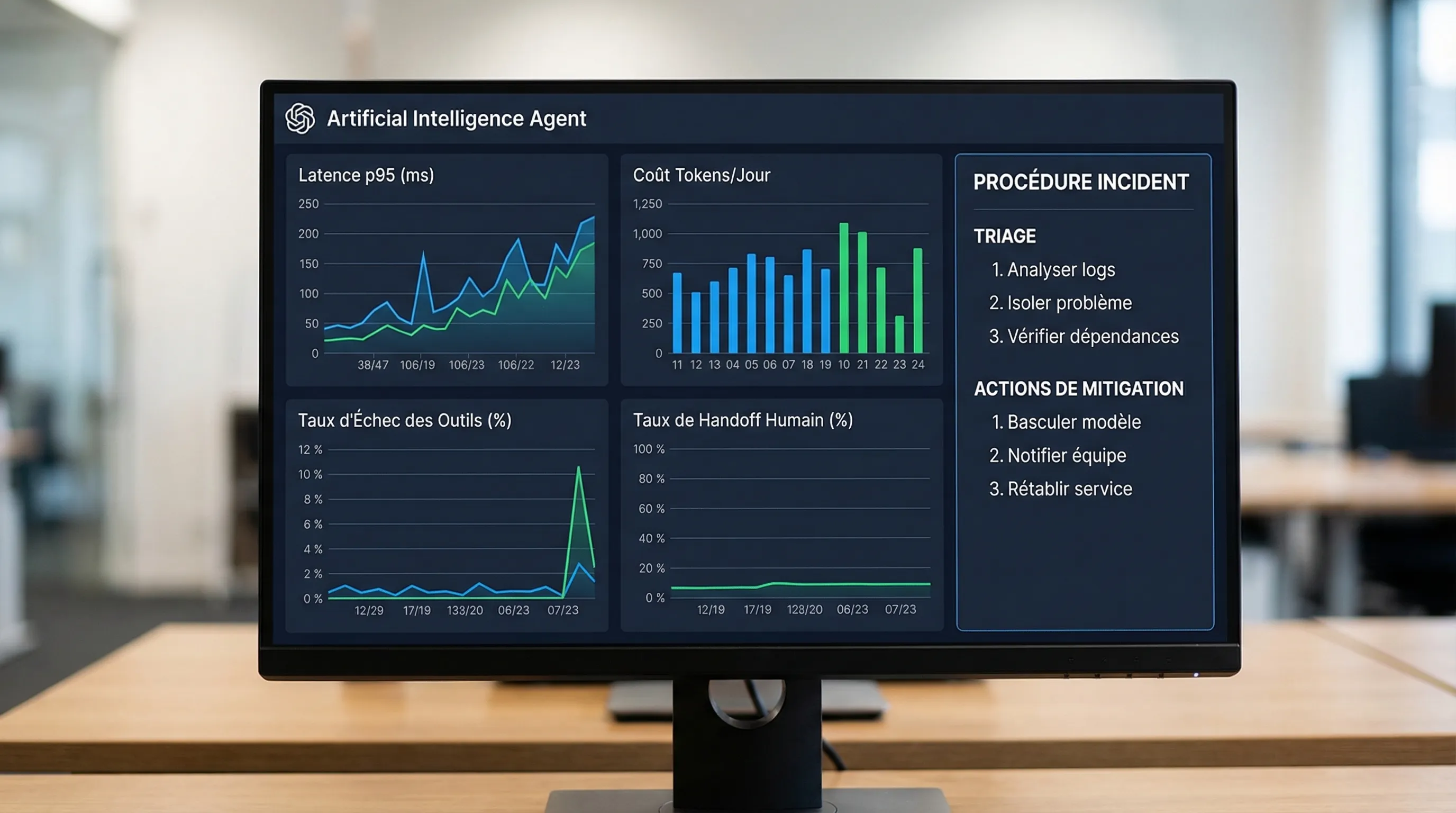
Observabilité: les 8 métriques qui évitent les angles morts
Sans sur-optimiser, mettez au moins:
Latence p50 et p95
Taux d’erreur global
Taux d’échec par outil (par action)
Coût tokens par session et par tâche
Taux de handoff humain
Taux de refus par policy (et raisons)
Taux de réponses avec citations (si RAG)
Taux d’“undo” ou correction utilisateur (signal qualité)
5) Sécurité et conformité: une approche proportionnée, mais explicite
Un agent est un multiplicateur de risques, car il peut accéder à des données et déclencher des actions. Sans tomber dans une gouvernance lourde, appliquez une discipline simple:
Gestion des secrets (jamais dans les prompts, rotation, coffre)
Filtrage PII (minimisation, masquage, règles par canal)
Journalisation utile (traces exploitables, mais données maîtrisées)
Revue des actions (au moins au début, validation humaine)
Si vous avez besoin d’un référentiel de gestion des risques IA, le cadre NIST AI RMF est une référence largement utilisée pour structurer des contrôles sans bloquer la delivery.
6) Plan d’exécution réaliste (en cycles courts)
Pour une PME ou une scale-up, le piège est de viser un “agent généraliste”. À la place, ciblez un flux critique et livrez en itérations:
Semaine 1: contrat d’agent, sources, actions autorisées, schémas d’inputs, premier golden set.
L’objectif n’est pas “d’avoir un agent”, mais d’avoir un agent exploitable.
Frequently Asked Questions
Quelle est la différence entre un agent IA et un copilot? Un copilot assiste l’utilisateur (suggestions, rédaction, recherche). Un agent exécute des étapes et peut déclencher des actions outillées. Plus il agit, plus l’architecture, les tests et le runbook deviennent indispensables.
Quels sont les éléments non négociables d’une architecture d’agent en production? Une séparation claire entre orchestration, contexte (RAG), connecteurs outils, garde-fous (policies) et observabilité. Sans cette séparation, vous perdez la testabilité et la maîtrise des risques.
Comment tester un agent IA si ses réponses ne sont pas déterministes? Avec un golden set de scénarios, des métriques de scorecard (utilité, exactitude, sécurité), des tests d’outils déterministes (mocks, contract tests) et une validation en pilote contrôlé avant production progressive.
Qu’est-ce qu’un runbook d’agent IA doit absolument contenir? Des SLO, des modes dégradés, des procédures d’incident, un mécanisme de rollback (prompts, règles, index, connecteurs) et un plan de maintenance des sources (RAG).
Quelles métriques suivre pour éviter les coûts surprises? Coût par session et par tâche, tokens par étape, latence p95, taux de boucles/retries, et taux d’échec des outils. Fixez un budget et des limites par utilisateur ou par workflow.
Quand faut-il passer d’un pilote à une vraie mise en production? Quand la scorecard atteint un seuil acceptable sur qualité, sécurité, fiabilité outils et coûts, avec un runbook opérationnel et un propriétaire métier clairement identifié.
Besoin d’un agent IA réellement exploitable (pas une démo)?
Impulse Lab accompagne les PME et scale-ups sur toute la chaîne: audit d’opportunités IA, développement sur mesure (web et IA), automatisation et intégrations, et formation à l’adoption. Si vous voulez cadrer un cas d’usage agent-ready, définir un protocole de tests, et livrer une V1 instrumentée en cycles courts, vous pouvez nous contacter via Impulse Lab.