Intelligence artificielle comment ça marche : version dirigeant
Intelligence artificielle
Stratégie IA
Outils IA
Gestion des risques IA
ROI
Quand un dirigeant tape une question dans un outil d’IA et obtient une réponse “qui semble intelligente”, la tentation est de croire qu’il s’agit d’un moteur de recherche amélioré, ou d’un logiciel qui “comprend” vraiment.
avril 25, 2026·9 min de lecture
Quand un dirigeant tape une question dans un outil d’IA et obtient une réponse “qui semble intelligente”, la tentation est de croire qu’il s’agit d’un moteur de recherche amélioré, ou d’un logiciel qui “comprend” vraiment.
En réalité, l’intelligence artificielle moderne est un assemblage de briques (modèles, données, règles, intégrations, garde-fous) dont le comportement dépend fortement du contexte et du design produit. Comprendre “comment ça marche” vous aide surtout à mieux décider : quoi déployer, à quel risque, avec quel ROI, et quelles preuves exiger.
Intelligence artificielle : de quoi parle-t-on (vraiment) ?
En entreprise, on regroupe sous “IA” plusieurs familles de systèmes.
Famille d’IA
Comment ça marche (simplifié)
Exemples typiques
Quand c’est pertinent
IA à règles
Si A alors B, arbres de décision, règles métier
Routage de tickets, scoring simple, anti-fraude basique
Process stables, besoin d’explicabilité, peu de données
Machine learning “classique”
Apprend des corrélations à partir de données structurées
Prévision, churn, scoring, détection d’anomalies
Quand vous avez des historiques propres et des labels
Deep learning et IA générative (LLM)
Réseaux neuronaux capables de générer du texte, du code, des images
Assistants, Q&A documentaire, génération de contenu, copilotes
Quand le langage et les contenus non structurés dominent
Dans ce guide, on se concentre sur ce qui alimente l’explosion des usages depuis 2023 : les LLM (Large Language Models), c’est-à-dire les modèles de langage capables de produire du texte (et souvent plus). Si besoin, vous pouvez approfondir la définition dans le lexique Impulse Lab : LLM (Large Language Model).
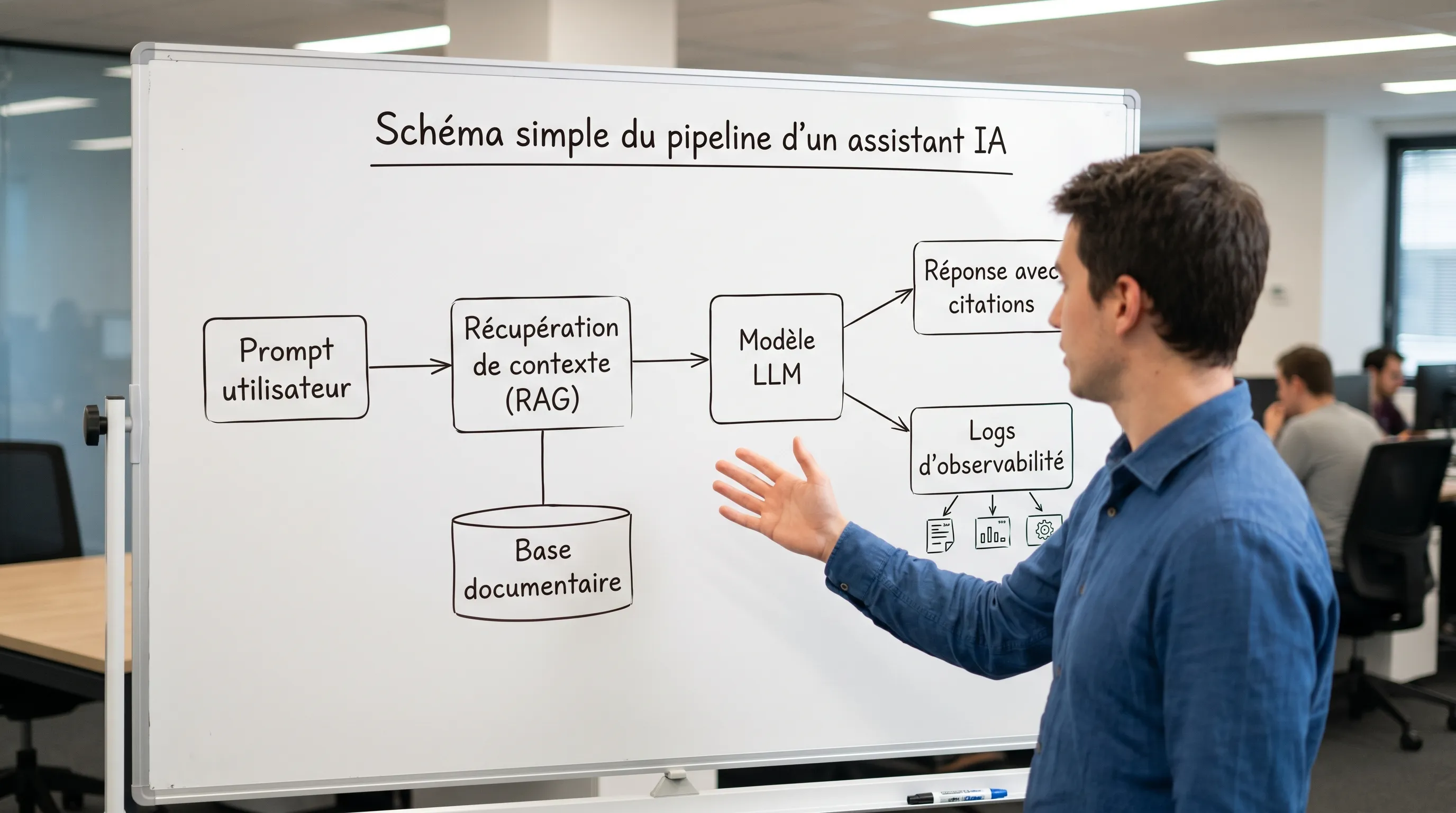
Intelligence artificielle comment ça marche : ce qui se passe quand vous écrivez un prompt
Voici la version “dirigeant” du chemin de bout en bout.
1) Votre prompt est transformé en unités manipulables (tokens)
Un LLM ne “lit” pas une phrase comme un humain. Il découpe votre texte en tokens, des morceaux de mots fréquents. Ce découpage influe sur :
le coût (souvent proportionnel au nombre de tokens)
la longueur maximale de contexte
certains comportements (langues, jargon, formats)
2) Le modèle prédit la suite la plus probable
Le principe de base d’un LLM est simple à énoncer : prédire le prochain token à partir des tokens précédents.
Le modèle ne va pas “chercher” une vérité.
Il produit une suite statistiquement plausible compte tenu de ce qu’il a appris.
C’est aussi la racine d’un phénomène central en entreprise : une réponse fluide peut être fausse.
Pour situer l’origine technique : la plupart des LLM modernes reposent sur l’architecture Transformer, popularisée par le papier “Attention Is All You Need” (2017) (arXiv).
3) Il y a un réglage implicite entre créativité et fiabilité
La sortie n’est pas déterministe à 100 %. Selon les réglages (température, sampling, etc.), le modèle peut :
être plus “créatif” (utile en brainstorming)
ou plus stable (utile en production, support, conformité)
Pour un usage business, la question n’est pas “quel modèle ?” mais “quel niveau de fiabilité exigé ?” et comment on le garantit (contexte, sources, règles, validations).
4) Sans données d’entreprise, le modèle est “aveugle” sur votre réalité
Un LLM grand public ne connaît pas :
vos procédures à jour
votre catalogue, vos conditions, vos exceptions
votre CRM, vos tickets, vos contrats
Sans connexion à des sources de vérité, il “complète les trous”. D’où l’intérêt du RAG (Retrieval-Augmented Generation) : on récupère des documents internes pertinents, puis on les injecte dans le contexte du modèle pour obtenir une réponse ancrée et traçable.
Entraînement vs utilisation : deux phases à ne pas confondre
Beaucoup de malentendus viennent de là.
Entraînement (training) : ce qui rend le modèle “compétent”
Pendant l’entraînement, le modèle apprend des régularités sur de très grands volumes de données. Pour un dirigeant, l’idée clé est : ce que le modèle sait est lié à son corpus et à sa date d’entraînement.
On distingue souvent :
Pré-entraînement : apprentissage généraliste sur de grands corpus.
Fine-tuning (affinage) : adaptation à un domaine, un style, un format.
Alignement (ex. RLHF) : ajustement pour réduire certains comportements indésirables et mieux suivre des instructions.
Inférence (inference) : ce que vous payez au quotidien
En production, vous payez surtout :
les tokens en entrée et en sortie
la latence
la maintenance des sources de vérité (connaissances, politiques)
l’intégration et le “run” (logs, alertes, qualité, sécurité)
C’est une raison fréquente des déceptions : le budget n’est pas seulement “le modèle”, c’est le système complet.
Pourquoi l’IA se trompe (et pourquoi ce n’est pas un détail)
En contexte entreprise, une erreur coûte plus cher qu’une réponse un peu lente.
Les hallucinations : réponses plausibles, non garanties
Un LLM peut inventer :
une politique de remboursement
une spécification produit
une cause racine technique
Ce n’est pas un bug marginal. C’est un comportement possible quand :
le contexte fourni est insuffisant
la question est ambiguë
la réponse “attendue” ressemble à des motifs appris
En pratique, on traite ça par architecture (RAG, citations, refus de répondre, escalade humaine) et par pilotage (tests, mesures, monitoring).
Les attaques spécifiques aux LLM (prompt injection)
Dès qu’un modèle lit des contenus externes (pages web, emails, tickets), il peut être manipulé par des instructions cachées. C’est pour cela que la sécurité ne se limite pas au chiffrement.
Pour les patterns de déploiement et de contrôle, voir :
Quand on ajoute une capacité d’action (création de ticket, mise à jour CRM, relance), on entre dans le monde des agents IA. Définition : Agent IA.
Si vous entendez parler de standardisation des connecteurs et du contexte, regardez aussi : Model Context Protocol (MCP).
Comment un dirigeant peut “auditer” une IA en 10 minutes (sans être technique)
Vous n’avez pas besoin de lire du code. Vous avez besoin d’obtenir des réponses nettes.
1) Quel est le cas d’usage, et quelle KPI décide du succès ?
Exemples de KPIs “dirigeant-friendly” :
% de tickets résolus sans escalade (avec contrôle qualité)
temps moyen de traitement (AHT) et taux de réouverture
taux de conversion rendez-vous, ou coût par opportunité
temps gagné par personne sur un workflow précis
Si la KPI n’existe pas, vous achetez une démo.
2) Quelles sont les sources de vérité, et qui en est propriétaire ?
Une IA “support” sans base documentaire maintenue devient rapidement dangereuse. Demandez :
quelles pages, quels documents, quelles règles
comment on gère les versions
qui valide une mise à jour
3) Quel est le mécanisme anti-hallucination ?
Réponses acceptables :
RAG avec citations obligatoires
réponses “je ne sais pas” autorisées
escalade humaine sur cas sensibles
tests sur un jeu de cas réels (golden set)
4) Quelles données sortent de l’entreprise, et avec quelles garanties ?
Le sujet est juridique et sécurité. Côté UE, le cadre évolue fortement avec l’AI Act (voir la page de référence de la Commission européenne : EU AI Act).
Un LLM “comprend-il” ce qu’il dit ? Il manipule des probabilités sur des séquences de tokens. Il peut produire du raisonnement utile, mais sans garantie de vérité. D’où l’importance des sources, des garde-fous et des tests.
Faut-il entraîner un modèle sur nos données pour que ça marche ? Pas forcément. Beaucoup de cas d’usage démarrent plus vite avec du RAG (connexion aux sources de vérité) et des règles d’orchestration. Le fine-tuning devient intéressant quand vous avez des formats très spécifiques, beaucoup d’exemples, ou des besoins de style/comportement stables.
Pourquoi l’IA “hallucine” alors qu’elle semble sûre d’elle ? Parce que son objectif est de produire une suite plausible, pas de dire vrai. Si l’information manque ou est contradictoire, le modèle peut compléter. On réduit cela avec RAG, citations, refus de répondre, et escalade humaine.
Quel est le plus gros piège pour un dirigeant ? Acheter une démo au lieu d’un système mesuré. Une IA utile a une KPI, des sources de vérité, une intégration au workflow, et un plan de run.
Comment démarrer sans prendre de risque ? Choisissez un cas fréquent et mesurable, lancez une V1 instrumentée sur un périmètre clair, puis décidez sur données. Une trame robuste est la feuille de route 30-60-90 jours.
Passer de “ça répond” à “ça crée de la valeur”
Comprendre intelligence artificielle comment ça marche est utile, mais la valeur arrive quand l’IA est intégrée à vos outils, encadrée par des garde-fous, et pilotée par des KPIs.
Impulse Lab accompagne les PME et scale-ups avec :
des audits d’opportunités IA (prioriser les cas d’usage par ROI et risque)
du développement sur mesure (plateformes web et IA, intégrations, automatisations)
de la formation à l’adoption (règles d’équipe, qualité, sécurité)
Si vous voulez une trajectoire pragmatique, sans “POC cimetière”, vous pouvez nous contacter via impulselab.ai.
Edge AI cloud AI : quel choix selon vos contraintes
En 2026, beaucoup de dirigeants ont compris qu’il ne suffit plus de “mettre de l’IA” dans un processus. La vraie question est plus opérationnelle : **où l’IA doit-elle tourner pour créer de la valeur sans ajouter de risque, de lenteur ou de complexité inutile ?**