Advanced Conversational Agent: RAG, Tool-Calling, and Metrics
Intelligence artificielle
Stratégie IA
Outils IA
Conception conversationnelle
A chatbot that "answers well" is no longer a competitive advantage. In 2026, the difference lies in the ability to **connect AI to your sources of truth (RAG)**, **trigger real actions (tool-calling)**, and **prove impact with reliable metrics**. It is this triptych that transforms...
March 09, 2026·9 min read
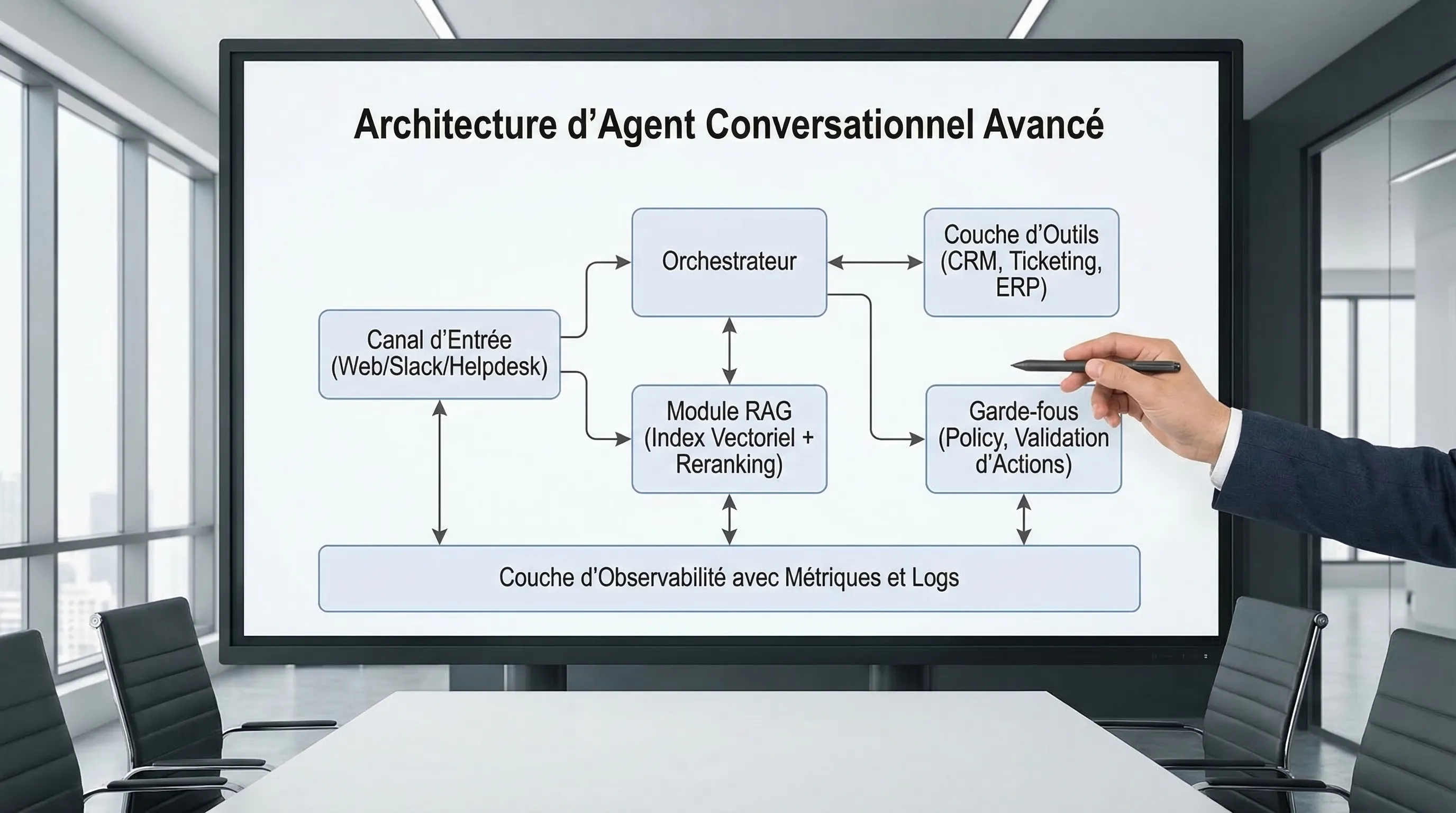
A chatbot that "answers well" is no longer a competitive advantage. In 2026, the difference lies in the ability to connect AI to your sources of truth (RAG), to trigger real actions (tool-calling), and then to prove impact with reliable metrics. It is this triptych that transforms a simple chat into an advanced conversational agent usable in production, on a site, in a helpdesk, or in an internal tool.
The objective of this article is pragmatic: to give you a reference architecture, design points that avoid "magic demos," and a measurement framework to steer quality, costs, and ROI.
What we really call an "advanced conversational agent"
An advanced conversational agent is not just a more powerful model. It is a system that:
understands an intent (question, task, action request),
anchors itself in verifiable context (documents, CRM, helpdesk, knowledge base),
acts via tools (create a ticket, search for an order, schedule an appointment),
is accountable (logs, sources, metrics, guardrails).
If you want a more "system" definition, you can also start from the notion of an AI agent (perception, decision, action) and apply it to conversation.
Most failures come from bad scoping: we expect a chat to do everything, everywhere, for everyone. A robust agent has, on the contrary, an explicit contract: scope, authorized sources, permitted actions, failure criteria, human escalation.
RAG: The block that transforms chat into a reliable system
RAG answers a simple need: an LLM is strong at formulating and reasoning, but it is not your knowledge base. RAG serves to anchor the answer to a source of truth.
transactional data (orders, invoices, delivery status).
The last two categories often require stricter access controls, and sometimes routing through tool-calling rather than RAG (example: "where is my order?").
2) Chunking and document quality
Average RAG on bad documents remains average RAG. Practical points that recur:
documents up to date, versioned, with owners,
structure (headings, sections),
removal of duplicates and "dead" pages,
naming rules, and useful metadata (product, country, date, confidentiality).
3) Retrieval, reranking, and "question rewriting"
In production, quality is rarely "a single vector store and done." Gains come from small improvements:
query rewriting (reformulating the question to search better),
reranking (reordering retrieved passages to maximize relevance),
citations (links to passages, titles, sources).
If you want to go further on industrialization, you can complement this with the Impulse Lab article on robust RAG in production.
4) Conversational memory: useful, but dangerous without a contract
Many products add "memory" too early. For an advanced agent, first ask:
What must be memorized? (preferences, account context, ticket history)
How long? (session, 30 days, 1 year)
Who can see it? (support, admin, user)
How does the user correct or delete it?
Without these answers, you create errors that are hard to diagnose and unnecessary GDPR risks.
Tool-calling: Moving from "I answer" to "I do"
Tool-calling (function calling, tool use) refers to the model's ability to trigger a structured action: call an API, read a system, create or update an object (ticket, lead, order). Editors document these mechanisms widely, for example on the OpenAI (Function Calling) side and Anthropic (Tool use) side.
The 3 most profitable action patterns in SMBs and scale-ups
Pattern 1: "Lookup" (read)
The agent queries a system then answers.
Examples: order status, SLA, last invoice, slot availability.
Why it's profitable: low risk, immediate value, excellent for starting.
Pattern 2: "Create/Update" (write) with preview
The agent prepares an action, then asks for confirmation.
Examples: create a pre-filled ticket, register a qualified lead, generate a draft quote.
Why it's critical: this is where agents become dangerous if you don't impose a validation step.
Pattern 3: "Orchestration" (multi-tool) with limited autonomy
The agent chains several steps, but remains supervised.
Examples: qualify a request, check eligibility, create the ticket, notify Slack, update the CRM.
Indispensable guardrails for tool-calling
Tool-calling is not a "feature," it is a risk surface. Minimal guardrails:
Scopes and permissions: an agent only has access to necessary APIs and objects.
Explicit validation: for any action that has a client, financial, or legal impact.
Idempotence: a retry must not create two tickets.
Logging: keep the decision, parameters, result, and identity.
Injection detection: part of security is linked to prompt injection, documented in resources like the OWASP Top 10 for LLM Applications.
Metrics: The true "advanced" criterion in production
An advanced conversational agent is steered like a product: we don't just measure "does it work," we measure how much it brings in, at what cost, and with what level of risk.
To avoid confusion, use a 4-layer structure (widely used in product environments):
Business Impact (ROI)
Process Performance (operations)
User Experience (adoption and satisfaction)
Technical and AI Quality (reliability, cost, latency)
Minimal dashboard (to maintain weekly)
Layer
Metric
What it proves
Example alert
Business
Deflection rate (support) or Qualified appointments (sales)
Value creation
Deflection goes up, but CSAT goes down
Process
Average resolution time (or first response time)
Operational gain
Faster answers, but more escalations
Experience
Completion rate (goal reached without human)
Real utility
Many conversations, few goals reached
AI/Tech
Rate of "no source" answers in RAG
Robustness
The model answers without proof on sensitive topics
AI/Tech
Cost per conversation (tokens + tools)
Cost control
Cost doubles after adding memory
AI/Tech
Latency p95
Perceived quality
p95 too high, user abandonment
If your use case is chatbot-oriented, the article AI chatbots: Essential KPIs to prove ROI complements this framework well with more specific metrics (support, sales, internal).
RAG metrics to track (otherwise you are flying blind)
Without falling into over-engineering, three families of signals are very actionable:
Retrieval quality: is the source relevant, or off-topic?
Grounding: is the answer supported by the cited passages?
Coverage: how many questions fall "out of base" (and must switch to human or another system)?
In practice, you will also need a golden set: a pack of representative questions, with expected answers and reference sources, to test offline before each evolution.
Evaluate and improve: offline, pilot, production
The classic trap is to test "by hand" for a week, then conclude. For an advanced conversational agent, adopt a leveled protocol.
Level 1: offline (before showing to users)
pack of scenarios (frequent questions, edge cases, sensitive data)
evaluation of RAG quality (sources, citations, contradictions)
tool tests (tool-calling) in sandbox environment
Level 2: controlled pilot (small volume, real users)
limited scope (one client segment, one product, one channel)
systematic human escalation if uncertainty
instrumentation from day 1 (events, costs, errors)
Level 3: progressive production
rollout by stages (10%, then 30%, then 100%)
continuous monitoring (quality, costs, incidents)
runbook: who does what when the system degrades
On AI governance, frameworks like the NIST AI RMF help structure risks, controls, and responsibilities, without turning your project into a gas factory (bureaucratic nightmare).
Security, compliance, and trust: The non-negotiables
An advanced conversational agent manipulates data and can trigger actions, so it must be designed as a sensitive system.
The points that recur most often in SMBs and scale-ups:
Data minimization: do not send more than necessary to the model.
Identity management: know who is speaking, and what rights to apply.
Environment separation: sandbox for actions, production for real.
Actionable logs: keep enough to audit, without storing unnecessarily.
Escalation policy: when the chat hands over, and how.
On the GDPR side, the most effective way is to avoid theoretical debates and start from a simple inventory: what data, for what purpose, what duration, what processors, what controls.
Realistic deployment plan (30 days) for a measurable V1
Rather than aiming for a "universal agent," a fast and rational plan consists of delivering a narrow but instrumented V1.
Week 1: scoping and contract
Define:
1 unique use case (e.g., support triage, lead qualification, internal FAQ)
1 North Star metric (e.g., avoided tickets, qualified appointments, time saved)
the agent contract (scope, sources, actions, failures, escalation)
Week 2: useful RAG, not "perfect"
selection of high-value sources
indexing and minimal metadata
mandatory citations on sensitive topics
Week 3: tool-calling on a simple flow
1 or 2 tools maximum at the start
preview, confirmation, idempotence
logs and cost-per-action metrics
Week 4: pilot + decision
deployment on a small scope
weekly review of metrics
decision: scale, fix, or stop
It is this discipline (contract + integration + metrics) that moves from a "nice" chatbot to an advanced conversational agent that creates value.
When to go custom (and when to stay with a tool)
You can often start with a market tool if:
the scope is simple,
the data is not sensitive,
the integrations are standard,
measurement is possible.
Custom becomes relevant when:
you have specific integrations (ERP, internal tools),
you must guarantee traceability, citations, audit,
the agent triggers risky actions,
you want to control quality and cost in production.
Impulse Lab supports precisely this type of trajectory, via AI opportunity audits, adoption training, and the development of custom web and AI solutions, integrated into your existing tools. If you wish, we can scope an "agent-ready" use case together and define the measurable V1 to deliver in a few weeks.
AI at Work: 10 Tasks to Delegate Without Losing Control
AI at work is useful when it removes friction, not when it replaces business judgment. For SMEs and scale-ups, the right question isn't "what can AI do for me?", but rather: "what tasks can I delegate to it to save time while keeping control?"