AI APIs save weeks of development, but poor integration creates technical debt, exposes sensitive data, and complicates compliance. Building clean and secure integration models means defining architecture, data governance, and security controls early on.
December 09, 2025·8 min read
AI APIs save weeks of development, but when poorly integrated, they create technical debt, expose sensitive data, and complicate compliance. Building clean and secure integration models means defining architecture, data governance, and security controls very early on. Here are the approaches that work in 2025, with concrete patterns and actionable checklists.
Why a Specific Architecture for AI APIs
An AI API is not a simple calculation API. It often handles free text, potentially sensitive data, dynamic prompts, and non-deterministic responses. Three major consequences for your teams:
Quality is controlled by observability and continuous evaluation, not just unit tests.
Security must integrate risks specific to LLMs, such as prompt injection and contextual exfiltration.
Compliance requires a precise inventory of data sent to the provider, processing regions, and retention periods.
To structure all this, adopt a clear integration model, then apply clean and traceable engineering principles.
7 AI API Integration Models: When to Use Them and How to Secure Them
Model
When to use
Advantages
Key risks
Mitigation measures
1. Backend to provider
Simple cases, controlled backends, non-critical data
Simplicity, low latency
Secret leakage, PII exposure in logs
Secrets in vault, PII masking, structured logs, retention policies
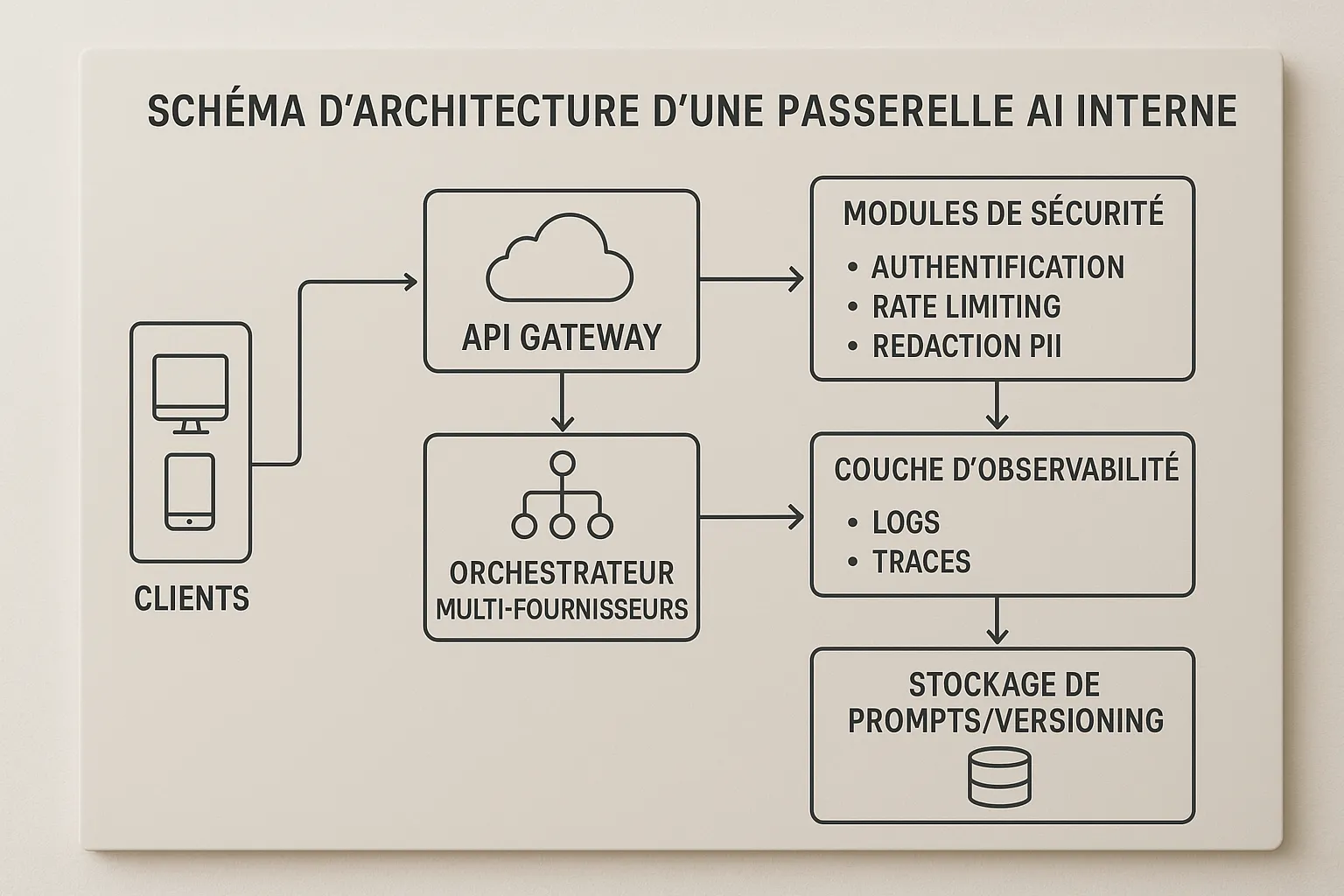
2. Internal AI Gateway
Multiple products or models, need for governance
Central controls, quotas, A/B tests, multi-provider abstraction
Single point of failure
High availability, circuit breakers, rate limiting, per-service policy
3. Client-side integration with ephemeral token
Prototyping, cases without sensitive data
Direct experience, client-side costs
Token exposure, quota bypass
Very short signed tokens, restricted scopes, mandatory minimal proxy
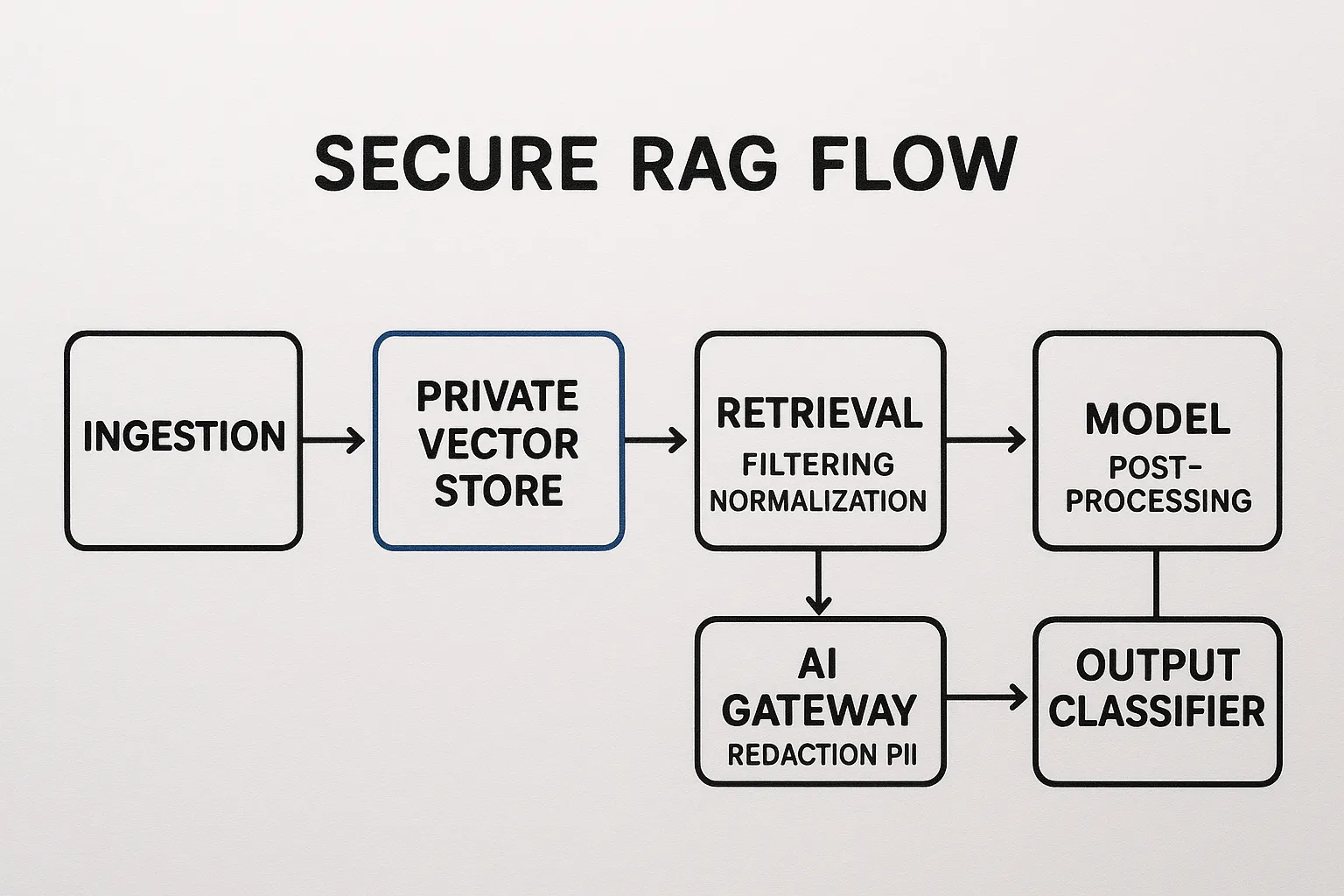
4. Orchestrated RAG (retrieve then generate)
Internal knowledge, document bases
Contextualized responses, continuous updates
Injection via documents, index leakage
Context sanitization, trust signals, source control
5. Function calling and controlled tools
Operational agents, delegated business actions
Automation, action traceability
These models are not mutually exclusive. Many teams combine an internal AI gateway with RAG for knowledge and batch for background processing.
"Clean" Architecture Principles for AI APIs
Separate orchestration from the application. Centralize prompts, policies, tests, and metrics in a dedicated layer, rather than dispersing logic across every service.
Stable contracts. Define strict input and output schemas (JSON Schema). Manage versioning via /v1, /v2, with deprecation and planned migration.
Industrial prompt management. Templating, typed variables, regression tests on a set of examples. Version prompts and parameters by use case.
Idempotency and retries. AI calls fail sometimes; plan retries with backoff and idempotency keys to avoid duplications.
Costs under control. Budgets per product, token caps, deterministic caching of stable results, alerts on consumption drift.
End-to-end observability. Distributed traces, request correlation, prompt, RAG context, output, and cost. PII filtering in logs.
For telemetry, standardize your traces with OpenTelemetry, then aggregate in your preferred observability stack. Reference: OpenTelemetry.
Security and Compliance by Design
Secrets and machine identities. Store provider keys in a KMS or vault. Regular rotation, role-based access, never in shared environment variables.
Authentication and authorization. Machine-to-machine via OAuth2 client credentials, minimal scopes, per-service policy at your gateway level.
Data protection. Encryption in transit and at rest, strict minimization of sent fields, pseudonymization where possible. The CNIL details pseudonymization here: CNIL, pseudonymization.
Safe logging. Never raw prompts containing cleartext PII in logs. Automatic redaction before storage.
Defense against LLM threats. Manage prompt injection, overreliance, and data exfiltration according to the OWASP Top 10 for LLM Applications.
Classic API Security. Don't forget the fundamentals of the OWASP API Security Top 10: access control, rate limiting, strict input validation.
Governance and compliance. Categorize data, document flows, choose the appropriate processing region, specify retention periods, establish legal bases. The CNIL summarizes AI and GDPR issues here: AI and GDPR, CNIL. For risk management, rely on the NIST AI RMF. On the AI Act, follow the application schedule and risk classification on the official Commission page: European AI Act.
Recommended Implementation Patterns
AI Gateway with Centralized Policies
A single entry point for all AI calls.
Policy per client or product: allowed models, budgets, regions, PII redaction.
Structured logs, traceability, A/B testing, and multi-provider fallback.
Minimal example in Python, to illustrate essential guardrails:
from fastapi import FastAPI, Header, HTTPException
import httpx, time
app = FastAPI()
ALLOWED_MODELS = {"gpt-4o", "claude-3-5-sonnet"}
BUDGET_TOKENS = {"appA": 2_000_000}
async def redact_pii(text: str) -> str:
# Replace with real PII detection
return text.replace("@", " [at] ")
@app.post("/ai/generate")
async def generate(payload: dict, x_client_id: str = Header("")):
if x_client_id not in BUDGET_TOKENS:
raise HTTPException(403, "unknown client")
model = payload.get("model")
if model not in ALLOWED_MODELS:
raise HTTPException(400, "unauthorized model")
prompt = await redact_pii(payload.get("prompt", ""))
try:
async with httpx.AsyncClient(timeout=30) as client:
resp = await client.post(
"https://provider.example.com/v1/chat",
json={"model": model, "input": prompt},
headers={"Authorization": "Bearer <secret-from-kms>"}
)
resp.raise_for_status()
except httpx.HTTPError:
# Basic fallback, log and apply a circuit breaker in prod
raise HTTPException(502, "provider unavailable")
data = resp.json()
# Decrement budget based on consumed tokens
BUDGET_TOKENS[x_client_id] -= data.get("usage", {}).get("total_tokens", 0)
return {"output": data.get("output"), "usage": data.get("usage"), "ts": int(time.time())}
Secure and Controlled RAG
Private index, strict separation between source data and context sent to the model.
Context normalization, removal of HTML/scripts, addition of provenance metadata.
Security filter on context before calling the model, and output classifier.
Risk-Free Function Calling
Whitelist of functions and parameters, strict schemas.
Sandboxes for any action with external effects.
Human confirmation for sensitive operations (payment, deletion, privilege escalation).
Observability, Quality, and Costs
Traces and correlation. Trace every request with a correlation ID, from frontend to provider. Keep prompt, context, and response in masked form if necessary.
Continuous evaluation. Build a representative test set, run it with every change of prompt, model, or temperature. Track business quality metrics (accuracy of extracted fields, correct refusal rates, response time).
Predictable costs. Budgets per product, alerts on overage, cache for frequent requests. Use streaming and truncation strategies to limit tokens.
Quick Checklists
Before Sending the First Request
Data inventory and classification by sensitivity.
Legal basis for processing, consent if necessary, documented processing regions.
Explicit decision on the provider's training option using your data, if available.
Secrets vault and service roles configured, keys not stored in code.
Logging and traceability ready, with PII redaction.
During Integration
Integration pattern chosen, justified, and documented.
Policy for allowed models, timeout, retry, and circuit breaker.
Anti-injection controls on RAG context and output classifier.
Before Production Go-Live
Security and compliance review, DPIA if necessary.
Load tests, token budget, latency, and degradation plan.
Incident runbooks, key rotation, and revocation procedure.
30-Day Execution Plan
Week 1, Framing and Compliance. Map data flows, choose the integration model, draft the GDPR register, and assess risk with the NIST AI RMF. Decide on processing regions and retention policy.
Week 2, Platform and Guardrails. Deploy the AI gateway, configure secrets, rate limiting, PII masking, traces. Set up a RAG index if necessary, with a secure ingestion pipeline.
Week 3, Quality and LLM Security. Build your evaluation sets, automate tests, implement anti-injection guardrails and the output classifier. Add backup models and fallback strategy.
Week 4, Hardening and Go-Live. Load tests, chaos engineering, and simulated provider outage. Final compliance review, incident runbooks, cost and quality alerts, team training.
Common Mistakes to Avoid
Integrating client-side with a long-lived key exposed in the code.
Logging raw prompts containing emails, IDs, or case numbers.
Mixing prompt logic and security rules in every microservice instead of centralizing.
Letting models freely choose actions without a whitelist or sandbox.
Forgetting version migration, which freezes a model and blocks evolution.
FAQ
Do AI API providers train their models with my data by default? It depends on the provider and the plan. Check the data usage policy, disable learning on your content if possible, and formalize this decision in your processing register.
Can I call an AI API directly from a frontend application? Avoid for any real case. If you must prototype, use ultra-restricted ephemeral tokens generated by your backend and limit exposed functionalities.
How to protect against prompt injection attacks? Sanitize and normalize any injected context, add security instructions, limit available tools, use an output classifier, and monitor in production. Rely on the OWASP Top 10 LLM for specific threats.
What to do with PII in prompts? Minimize and pseudonymize at the source. Filter and mask in logs. The CNIL provides practical guidelines on pseudonymization.
RAG or fine-tuning to incorporate my knowledge? Start with RAG, which is faster and more governable. Fine-tuning comes later for specific gains, with strict control over datasets and leakage risks.
Ready to integrate AI APIs without compromising security and quality? Impulse Lab supports product and IT teams end-to-end, from AI opportunity audits to integration and training. We deliver every week, involve your teams throughout the project, and centralize tracking in a dedicated client portal. Tell us about your context and let's secure your AI roadmap: https://impulselab.ai