How Artificial Intelligence Works: Executive Edition
Intelligence artificielle
Stratégie IA
Outils IA
Gestion des risques IA
ROI
When an executive types a question into an AI tool and gets a "smart-sounding" answer, it's tempting to think it's an upgraded search engine or software that truly "understands."
April 25, 2026·8 min read
When an executive types a question into an AI tool and gets an answer "that sounds smart," the temptation is to believe it is an improved search engine, or software that truly "understands."
In reality, modern artificial intelligence is an assembly of building blocks (models, data, rules, integrations, guardrails) whose behavior depends heavily on context and product design. Understanding "how it works" primarily helps you make better decisions: what to deploy, at what risk, with what ROI, and what proof to demand.
Artificial intelligence: what are we (really) talking about?
In business, several families of systems are grouped under "AI".
AI Family
How it works (simplified)
Typical examples
When it's relevant
Rule-based AI
If A then B, decision trees, business rules
Ticket routing, simple scoring, basic anti-fraud
Stable processes, need for explainability, little data
"Classic" Machine Learning
Learns correlations from structured data
Forecasting, churn, scoring, anomaly detection
When you have clean historical data and labels
Deep learning and Generative AI (LLM)
Neural networks capable of generating text, code, images
In this guide, we focus on what has fueled the explosion of use cases since 2023: LLMs (Large Language Models), meaning language models capable of producing text (and often more). If needed, you can dive deeper into the definition in the Impulse Lab glossary: LLM (Large Language Model).
How artificial intelligence works: what happens when you write a prompt
Here is the "executive" version of the end-to-end journey.
1) Your prompt is transformed into manageable units (tokens)
An LLM does not "read" a sentence like a human. It breaks your text down into tokens, which are pieces of common words. This breakdown affects:
cost (often proportional to the number of tokens)
maximum context length
certain behaviors (languages, jargon, formats)
2) The model predicts the most likely continuation
The basic principle of an LLM is simple to state: predict the next token based on the preceding tokens.
The model does not go "searching" for a truth.
It produces a sequence that is statistically plausible given what it has learned.
This is also the root of a central phenomenon in business: a fluent answer can be false.
To pinpoint the technical origin: most modern LLMs rely on the Transformer architecture, popularized by the paper "Attention Is All You Need" (2017) (arXiv).
3) There is an implicit tuning between creativity and reliability
The output is not 100% deterministic. Depending on the settings (temperature, sampling, etc.), the model can:
be more "creative" (useful in brainstorming)
or more stable (useful in production, support, compliance)
For business use, the question is not "which model?" but "what level of reliability is required?" and how it is guaranteed (context, sources, rules, validations).
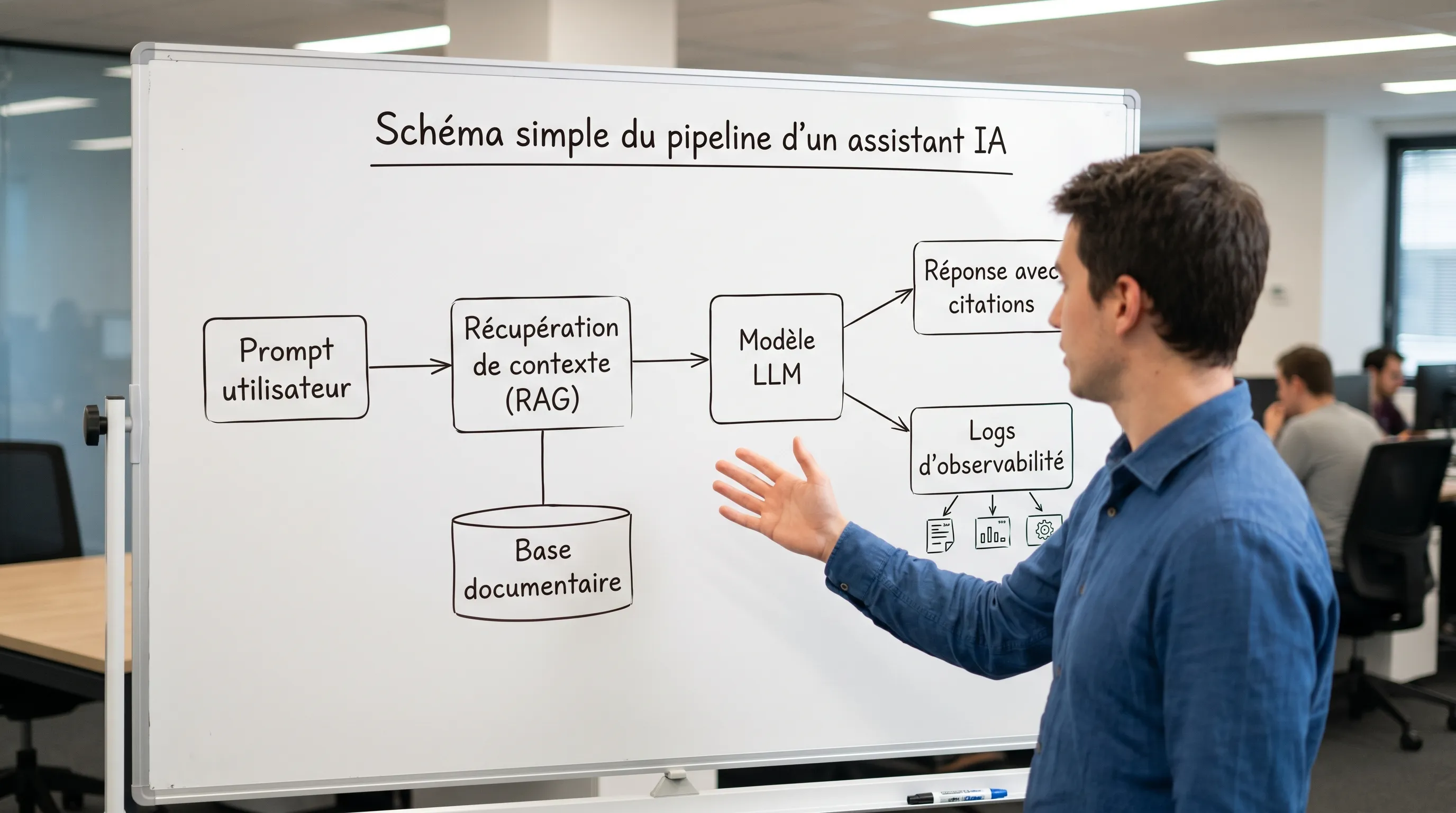
4) Without company data, the model is "blind" to your reality
A consumer-grade LLM does not know:
your up-to-date procedures
your catalog, your conditions, your exceptions
your CRM, your tickets, your contracts
Without a connection to sources of truth, it "fills in the blanks." Hence the value of RAG (Retrieval-Augmented Generation): relevant internal documents are retrieved, then injected into the model's context to obtain a grounded and traceable answer.
During training, the model learns patterns across very large volumes of data. For an executive, the key idea is: what the model knows is tied to its corpus and its training date.
We often distinguish between:
Pre-training: generalist learning on large corpora.
Fine-tuning: adaptation to a domain, a style, a format.
Alignment (e.g., RLHF): adjustment to reduce certain undesirable behaviors and better follow instructions.
Inference: what you pay for on a daily basis
In production, you primarily pay for:
input and output tokens
latency
maintenance of sources of truth (knowledge, policies)
integration and the "run" (logs, alerts, quality, security)
This is a frequent reason for disappointment: the budget is not just "the model", it is the entire system.
Why AI makes mistakes (and why it's not a minor detail)
In a business context, an error costs more than a slightly slow response.
Hallucinations: plausible but unverified answers
An LLM can invent:
a refund policy
a product specification
a technical root cause
This is not a marginal bug. It is a possible behavior when:
the provided context is insufficient
the question is ambiguous
the "expected" answer resembles learned patterns
In practice, this is handled through architecture (RAG, citations, refusal to answer, human escalation) and through management (testing, metrics, monitoring).
LLM-specific attacks (prompt injection)
As soon as a model reads external content (web pages, emails, tickets), it can be manipulated by hidden instructions. This is why security is not limited to encryption.
How an executive can "audit" an AI in 10 minutes (without being technical)
You don't need to read code. You need to get clear answers.
1) What is the use case, and what KPI determines success?
Examples of "executive-friendly" KPIs:
% of tickets resolved without escalation (with quality control)
average handling time (AHT) and reopen rate
meeting conversion rate, or cost per opportunity
time saved per person on a specific workflow
If the KPI doesn't exist, you are buying a demo.
2) What are the sources of truth, and who owns them?
A "support" AI without a maintained document base quickly becomes dangerous. Ask:
which pages, which documents, which rules
how versions are managed
who validates an update
3) What is the anti-hallucination mechanism?
Acceptable answers:
RAG with mandatory citations
"I don't know" answers allowed
human escalation for sensitive cases
testing on a set of real cases (golden set)
4) What data leaves the company, and with what guarantees?
This is a legal and security topic. On the EU side, the framework is evolving significantly with the AI Act (see the European Commission's reference page: EU AI Act).
Does an LLM "understand" what it says? It manipulates probabilities over sequences of tokens. It can produce useful reasoning, but without any guarantee of truth. Hence the importance of sources, guardrails, and testing.
Do we need to train a model on our data for it to work? Not necessarily. Many use cases start faster with RAG (connecting to sources of truth) and orchestration rules. Fine-tuning becomes interesting when you have very specific formats, many examples, or stable style/behavior needs.
Why does AI "hallucinate" when it seems so sure of itself? Because its goal is to produce a plausible continuation, not to tell the truth. If information is missing or contradictory, the model may fill in the blanks. We reduce this with RAG, citations, refusal to answer, and human escalation.
What is the biggest trap for an executive? Buying a demo instead of a measured system. A useful AI has a KPI, sources of truth, workflow integration, and a run plan.
How to start without taking risks? Choose a frequent and measurable use case, launch an instrumented V1 on a clear scope, then decide based on data. A robust framework is the 30-60-90 day roadmap.
Moving from "it answers" to "it creates value"
Understanding how artificial intelligence works is useful, but value arrives when AI is integrated into your tools, framed by guardrails, and driven by KPIs.
Impulse Lab supports SMEs and scale-ups with:
AI opportunity audits (prioritizing use cases by ROI and risk)
custom development (web and AI platforms, integrations, automations)
adoption training (team rules, quality, security)
If you want a pragmatic trajectory, without a "POC graveyard," you can contact us via impulselab.ai.