Agents autonomes : quand ça marche vraiment en entreprise
Intelligence artificielle
Stratégie IA
Automatisation
Les « agents autonomes » fascinent parce qu’ils promettent plus qu’un chatbot ou qu’un copilote : ils observent une situation, décident d’une suite d’actions, appellent des outils, puis bouclent jusqu’à atteindre un objectif. En pratique, ils peuvent créer beaucoup de valeur, mais seulement dans des...
février 23, 2026·10 min de lecture
Les « agents autonomes » fascinent parce qu’ils promettent plus qu’un chatbot ou qu’un copilote : ils observent une situation, décident d’une suite d’actions, appellent des outils, puis bouclent jusqu’à atteindre un objectif. En pratique, ils peuvent créer beaucoup de valeur, mais seulement dans des conditions assez précises. Sinon, ils deviennent un générateur d’incidents, de coûts variables, ou de dette opérationnelle.
L’objectif de cet article est simple : vous aider à décider quand un agent autonome marche vraiment en entreprise, comment cadrer le bon niveau d’autonomie, et comment le piloter sans transformer votre organisation en laboratoire permanent.
Ce qu’on appelle (vraiment) un agent autonome en entreprise
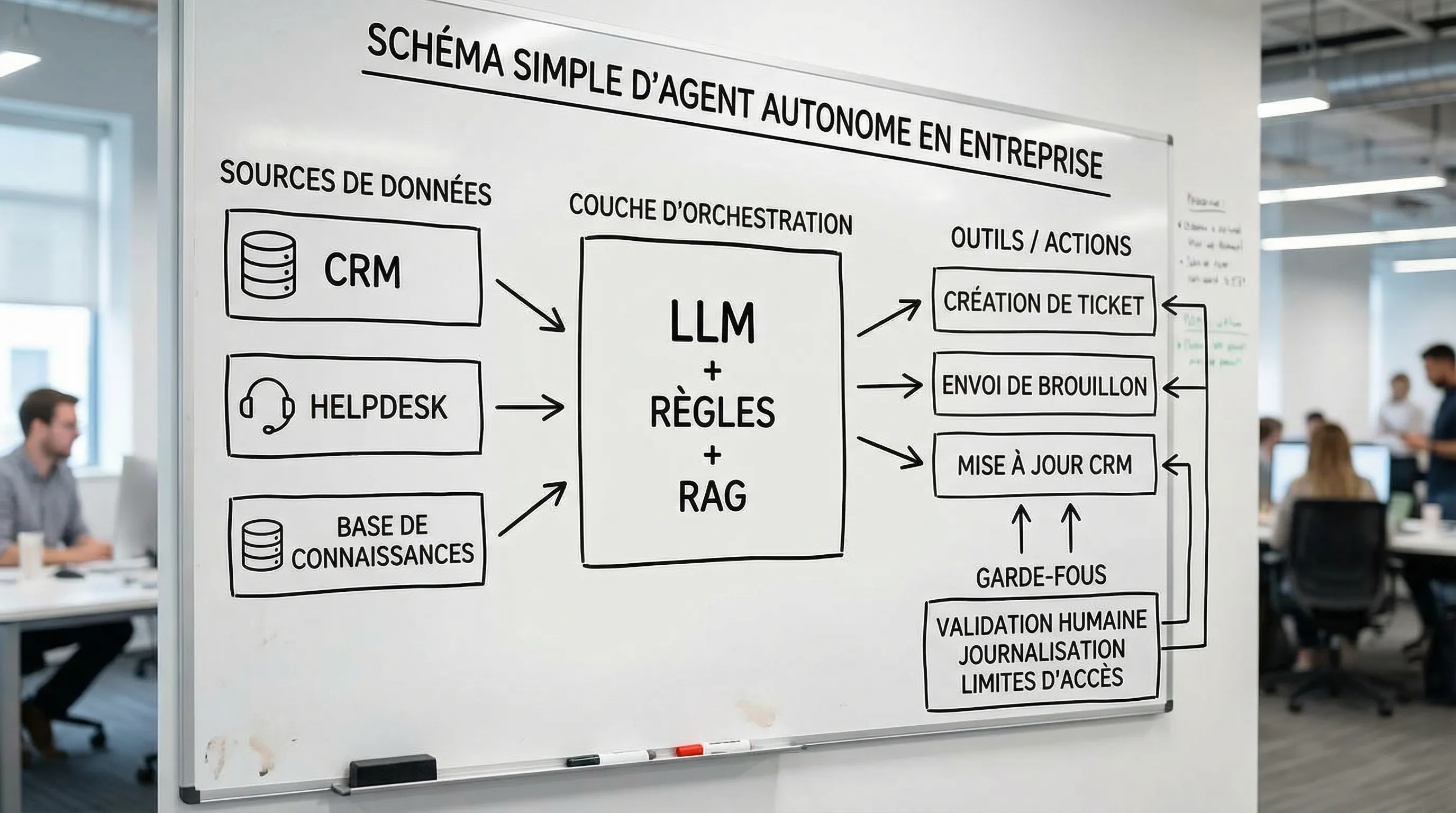
Dans un contexte business, un agent autonome est généralement un système basé sur un LLM, connecté à des données (souvent via RAG) et à des outils (CRM, ERP, helpdesk, messagerie, base documentaire, etc.), capable d’exécuter une boucle : planifier, agir, vérifier, corriger.
Pour éviter les malentendus, il est utile de distinguer agent, chatbot et automatisation déterministe.
Format
Ce que ça fait
Quand c’est le bon choix
Risque principal
Chatbot (conversation)
Répond, oriente, collecte des infos
Questions répétitives, triage, qualification
Hallucinations, mauvais routage
Copilote (assisté)
Propose, l’humain valide et exécute
Tâches à jugement humain, rédaction, analyse
Adoption faible si mal intégré
Automatisation déterministe (RPA, règles)
Exécute des règles stables
Process répétitifs, peu d’ambiguïté
Fragile si le process change
Agent autonome
Enchaîne des actions et s’auto-corrige
Workflows outillés, vérifiables, à forte fréquence
Actions non désirées, coût, sécurité
Si vous avez besoin d’une définition plus « système », vous pouvez aussi consulter l’entrée de lexique : agent IA.
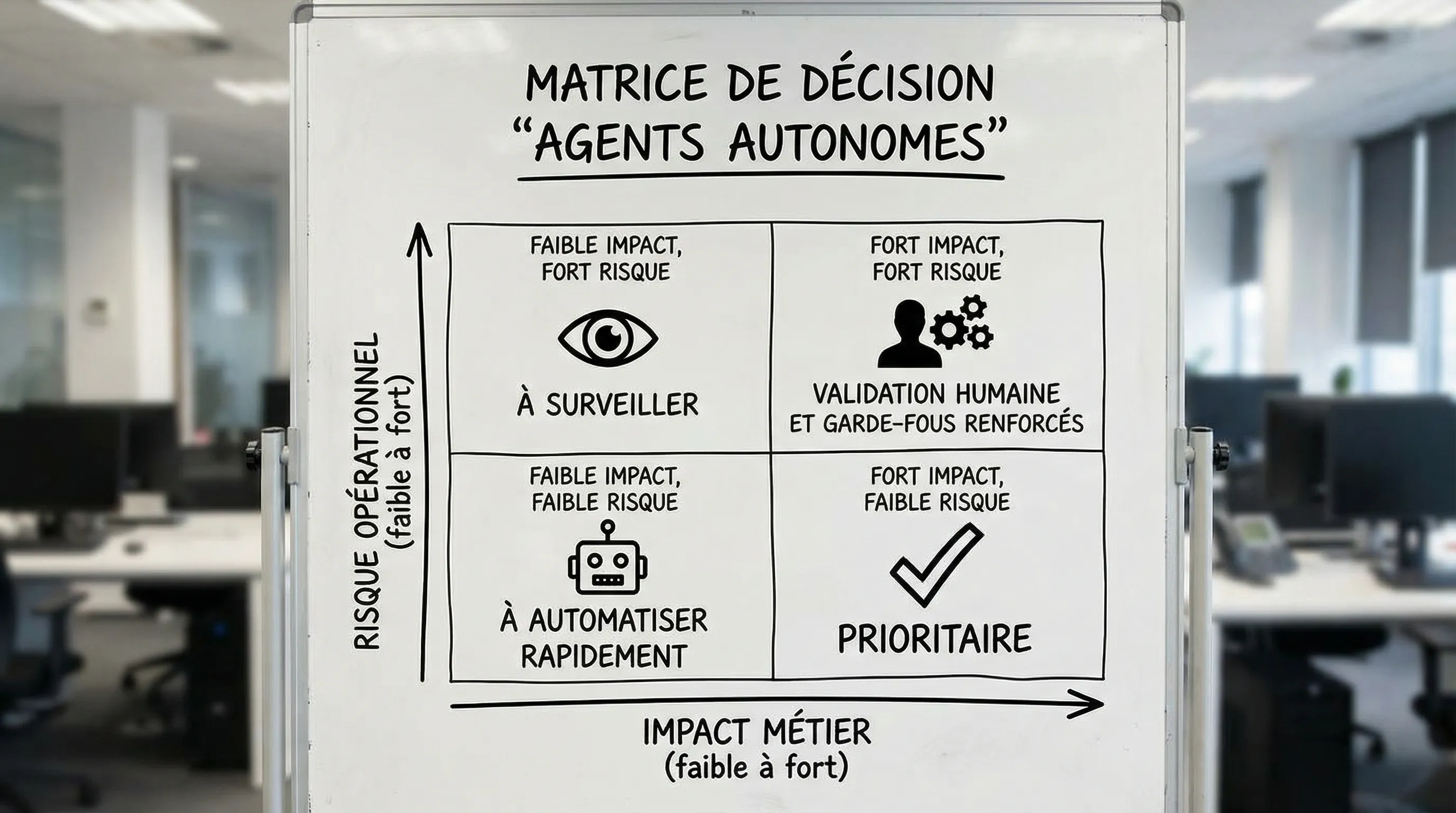
Quand les agents autonomes créent de la valeur : 6 conditions non négociables
Un agent autonome ne « marche » pas parce que le modèle est bon. Il marche parce que l’environnement est agent-compatible : objectifs clairs, données fiables, actions bornées, contrôles, et responsabilité métier.
1) Un objectif opérationnel, borné et testable
Un bon objectif d’agent ressemble à : « traiter une demande standard de A à Z avec vérification et escalade ». Un mauvais objectif ressemble à : « optimiser notre relation client ».
En pratique, l’objectif doit inclure :
un début (événement déclencheur : ticket, email, formulaire, changement de statut)
une fin (état atteignable : ticket résolu, devis envoyé, document complété)
des règles d’arrêt (timeout, nombre max d’itérations)
une définition de la qualité (ce qui est acceptable, ce qui doit escalader)
2) Un contexte fiable (et traçable), sinon l’agent improvise
Sans contexte fiable, un agent autonome devient créatif au mauvais endroit. En entreprise, cela impose généralement une brique de connaissance (RAG) et des sources gouvernées.
Pour le socle documentaire, voyez : RAG (lexique) et, si vous souhaitez standardiser les connexions aux outils, MCP (lexique).
3) Des actions « outillées » et réversibles
Les agents autonomes fonctionnent mieux quand ils agissent via des outils qui offrent :
des contrats stables (API, champs, statuts)
des prévisualisations (dry-run, brouillon)
de la réversibilité (annuler, revenir à l’état précédent)
de l’idempotence (répéter sans casser)
C’est l’inverse d’un agent qui clique dans une interface fragile ou qui « bricole » dans des boîtes mail sans garde-fous.
4) Des garde-fous proportionnés au risque (pas une « liberté totale »)
En entreprise, l’autonomie utile n’est pas « 100 % autonome ». C’est le bon niveau d’autonomie.
Un pattern robuste consiste à définir 3 zones :
Zone verte : l’agent agit seul (ex. enrichir une fiche, classer un ticket, proposer un plan)
Zone orange : l’agent agit avec validation humaine (ex. envoyer un email client, modifier une opportunité)
Zone rouge : l’agent n’agit pas, il assiste (ex. décisions réglementées, sanctions, crédit, RH sensibles)
5) Observabilité, tests et métriques, sinon vous ne pilotez rien
Un agent autonome est un mini-produit. Il doit être instrumenté.
Sans logs, traces d’outils appelés, taux d’escalade, raisons d’échec et coûts, vous ne pouvez pas l’améliorer, ni prouver le ROI.
Quand un agent se trompe, qui tranche ? Qui corrige la source ? Qui ajuste la règle d’escalade ?
Sans owner métier, vous aurez un agent « orphelin » : il marche en démo, puis il dérive en production.
Les cas d’usage où les agents autonomes marchent le mieux
Ceux qui marchent le mieux combinent fréquence, structure, outils, et vérifiabilité.
1) Triage et routage outillés (support, ops, service desk)
Exemples concrets :
qualifier un ticket, proposer une réponse, créer une tâche, assigner au bon groupe
vérifier la présence d’informations minimales, relancer automatiquement si incomplet
appliquer une politique de priorité avec explication
Pourquoi ça marche : beaucoup de volume, des règles métier existantes, et une sortie claire (ticket correctement routé).
2) Back-office documentaire avec validation (factures, contrats, dossiers)
L’agent peut : extraire, vérifier des champs, comparer à des règles, puis préparer une action (création d’écriture, demande de pièce, brouillon de réponse). Il devient très efficace si la validation humaine est simple.
3) Sales ops et CRM hygiene (environnement très outillé)
Quand le CRM est bien défini, l’agent peut :
résumer un échange (appel, email)
proposer une mise à jour de champs
créer les prochaines tâches
La clé : ne pas laisser l’agent « inventer » des informations client, et exiger une trace (sources, extraits, contexte).
Exemple : préparer une réunion hebdomadaire en allant chercher les métriques dans 2 ou 3 systèmes, produire un brief, puis ouvrir les tickets manquants.
Les cas où les agents autonomes marchent mal (ou coûtent trop cher)
Même en 2026, il y a des terrains défavorables. Voici les plus courants.
1) Décisions à fort enjeu et faible tolérance à l’erreur
Dès que l’erreur est coûteuse (juridique, RH sensible, conformité, finance réglementée), la bonne stratégie est souvent : copilote + validation stricte, pas autonomie.
2) Process flous ou politiques non écrites
Si les équipes « savent dans leur tête », l’agent ne peut pas être fiable. Vous devez d’abord transformer ce savoir en règles, exemples, et sources.
3) Données incohérentes, non gouvernées, ou difficiles d’accès
Sans inventaire de données, droits d’accès clairs et sources de vérité, l’agent passe son temps à deviner.
4) Tâches longues et multi-étapes sans vérification objective
Plus l’horizon est long, plus l’agent peut dériver. Les agents performants sont ceux qui bouclent sur des étapes courtes, vérifiables, avec arrêt.
Signal d’alerte
Ce que ça provoque
Alternative souvent meilleure
Les règles métier ne sont pas écrites
Décisions inconsistantes
Copilote + formalisation progressive
Pas de source de vérité
Hallucinations « plausibles »
RAG gouverné + citations
Actions irréversibles
Incidents, peur interne
Brouillons + validation + rollback
Pas de métriques
Impossible de prouver le ROI
Dashboard minimal, tests, logs
L’architecture minimale d’un agent autonome “production-grade”
Le piège est de croire qu’un agent = un prompt. Un agent autonome robuste ressemble plutôt à une petite plateforme.
Les briques typiques :
Orchestration : le “cerveau” qui planifie et exécute (et limite la boucle)
Point important : un déploiement “agent” sérieux exige presque toujours un registre des usages, des règles de données, et une stratégie d’escalade. Si vous structurez votre organisation IA, cette ressource peut aider : Organisation AI : rôles, gouvernance et responsabilités.
Méthode pragmatique : tester un agent autonome sans se tromper de pari
L’erreur la plus fréquente est de partir trop “agent autonome généraliste”. Une approche plus fiable consiste à découper l’autonomie et à prouver l’impact par étapes.
Un pilote en 4 jalons (sur 30 jours)
Jalons
Objectif
Livrables attendus
J1 à J5
Cadrer une tâche fréquente, définir zone verte/orange/rouge
Définition de done, règles d’arrêt, baseline KPI, risques
Les utilisateurs le veulent-ils dans leur workflow ?
Usage récurrent + retours terrain
Conclusion : l’autonomie n’est pas un objectif, c’est un réglage
En entreprise, les agents autonomes fonctionnent quand vous les considérez comme :
une capacité (agir dans des outils)
dans un workflow borné
avec des contrôles (humain, règles, logs)
et une mesure (KPI, coût, qualité)
La bonne question n’est pas « peut-on faire un agent ? » mais « quel niveau d’autonomie maximise le ROI sans augmenter le risque plus vite que la valeur ? »
Frequently Asked Questions
Un agent autonome, est-ce juste un chatbot plus avancé ? Non. Un agent autonome ne se limite pas à converser, il planifie et exécute des actions via des outils (API, CRM, helpdesk), avec une boucle de vérification et des règles d’arrêt.
Quel est le meilleur premier cas d’usage pour des agents autonomes en PME ? Le plus souvent : triage/routage de demandes (support, ops), ou back-office documentaire avec validation. Ce sont des flux fréquents, outillés, et mesurables.
Comment éviter qu’un agent autonome fasse n’importe quoi ? En bornant ses actions (permissions, outils autorisés), en imposant des validations sur la zone orange, en journalisant toutes les actions, et en testant sur des scénarios représentatifs.
Faut-il forcément du RAG pour un agent autonome ? Pas forcément, mais dès que l’agent doit s’appuyer sur des politiques, procédures, offres, ou données internes, le RAG (ou une source de contexte équivalente) devient une brique clé pour la fiabilité.
Les agents autonomes sont-ils compatibles avec le RGPD et l’AI Act ? Oui, mais ils imposent une approche “privacy et governance by design” : minimisation des données, droits d’accès, traçabilité, et garde-fous proportionnés au niveau de risque.
Faire le tri : où un agent autonome peut générer du ROI chez vous
Si vous hésitez entre copilote, automatisation classique et agents autonomes, Impulse Lab peut vous aider à auditer les opportunités, cadrer un pilote mesurable, puis développer et intégrer une solution adaptée à vos outils (CRM, support, ERP, data), avec formation et accompagnement à l’adoption.
Vous pouvez découvrir l’offre sur impulselab.ai et nous partager votre contexte (process, outils, contraintes) pour identifier le bon niveau d’autonomie, au bon endroit, avec les bons garde-fous.