API AI: modèles d’intégration propres et sécurisés
Intelligence artificielle
Stratégie IA
Confidentialité des données
Les API d’IA font gagner des semaines de développement, mais mal intégrées elles créent de la dette technique, exposent des données sensibles et compliquent la conformité. Construire des modèles d’intégration propres et sécurisés, c’est cadrer très tôt l’architecture, la gouvernance des données et l...
décembre 09, 2025·9 min de lecture
Les API d’IA font gagner des semaines de développement, mais mal intégrées elles créent de la dette technique, exposent des données sensibles et compliquent la conformité. Construire des modèles d’intégration propres et sécurisés, c’est cadrer très tôt l’architecture, la gouvernance des données et les contrôles de sécurité. Voici les approches qui fonctionnent en 2025, avec des patterns concrets et des checklists actionnables.
Pourquoi une architecture spécifique pour les API AI
Une API AI n’est pas une simple API de calcul. Elle manipule souvent du texte libre, des données potentiellement sensibles, des prompts dynamiques et des réponses non déterministes. Trois conséquences majeures pour vos équipes:
La qualité se contrôle par l’observabilité et l’évaluation continue, pas uniquement par des tests unitaires.
La sécurité doit intégrer des risques propres aux LLM, par exemple la prompt injection et l’exfiltration contextuelle.
La conformité exige un inventaire précis des données envoyées au fournisseur, des régions de traitement et des durées de rétention.
Pour structurer tout cela, adoptez un modèle d’intégration clair, puis appliquez des principes d’ingénierie propres et traçables.
7 modèles d’intégration d’API AI, quand les utiliser et comment les sécuriser
Modèle
Quand l’utiliser
Avantages
Risques clés
Mesures de mitigation
1. Serveur à fournisseur (backend to provider)
Cas simples, backends maîtrisés, données non critiques
Simplicité, latence faible
Fuite de secrets, exposition de PII dans logs
Secrets en coffre, masquage PII, journaux structurés, politiques de rétention
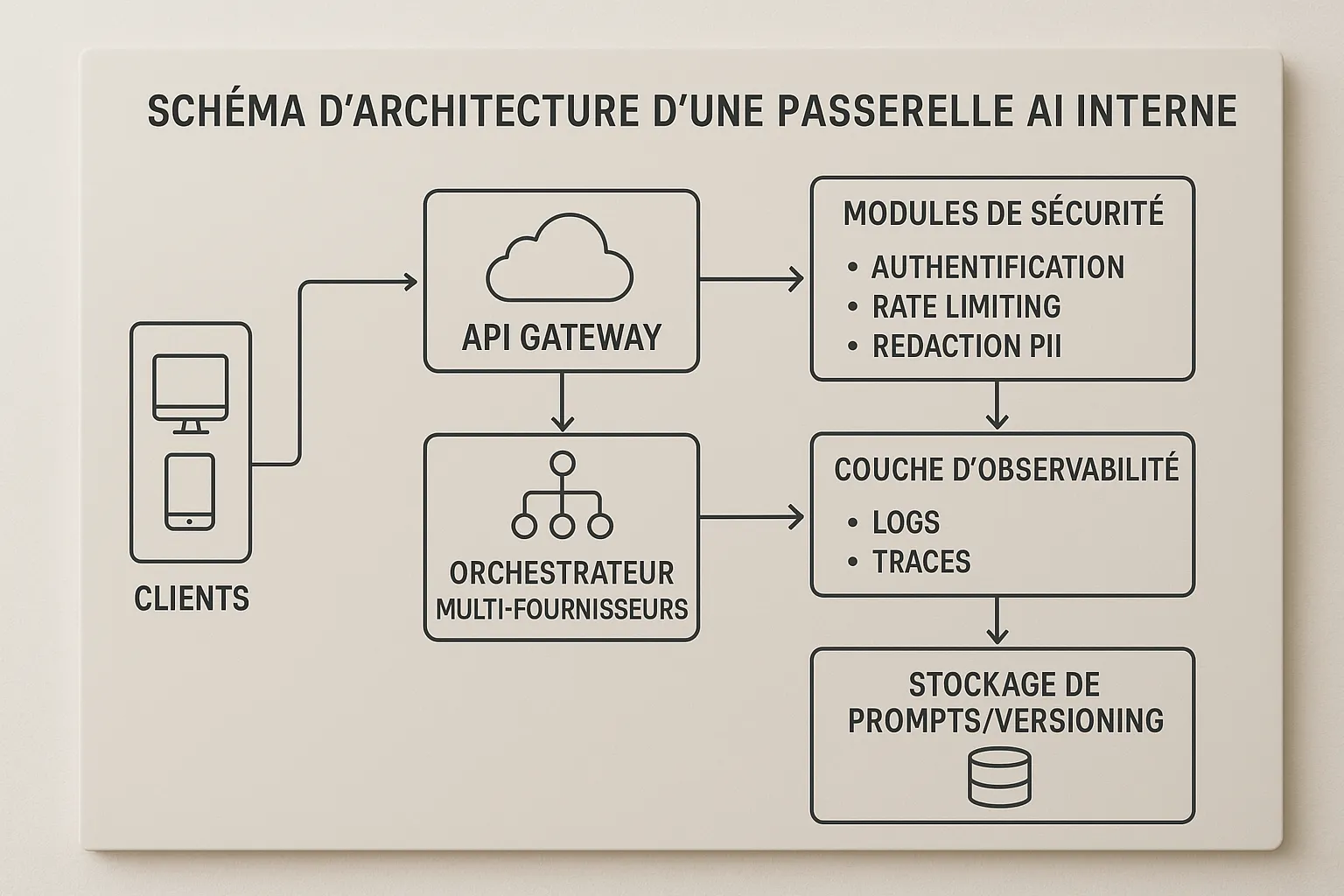
2. Passerelle AI interne (AI Gateway)
Plusieurs produits ou modèles, besoin de gouvernance
Haute dispo, circuit breakers, rate limiting, politique par service
3. Intégration côté client avec jeton éphémère
Prototypage, cas sans données sensibles
Expérience directe, coûts côté client
Exposition du token, contournement de quotas
Jetons signés très courts, scopes restreints, proxy minimal obligatoire
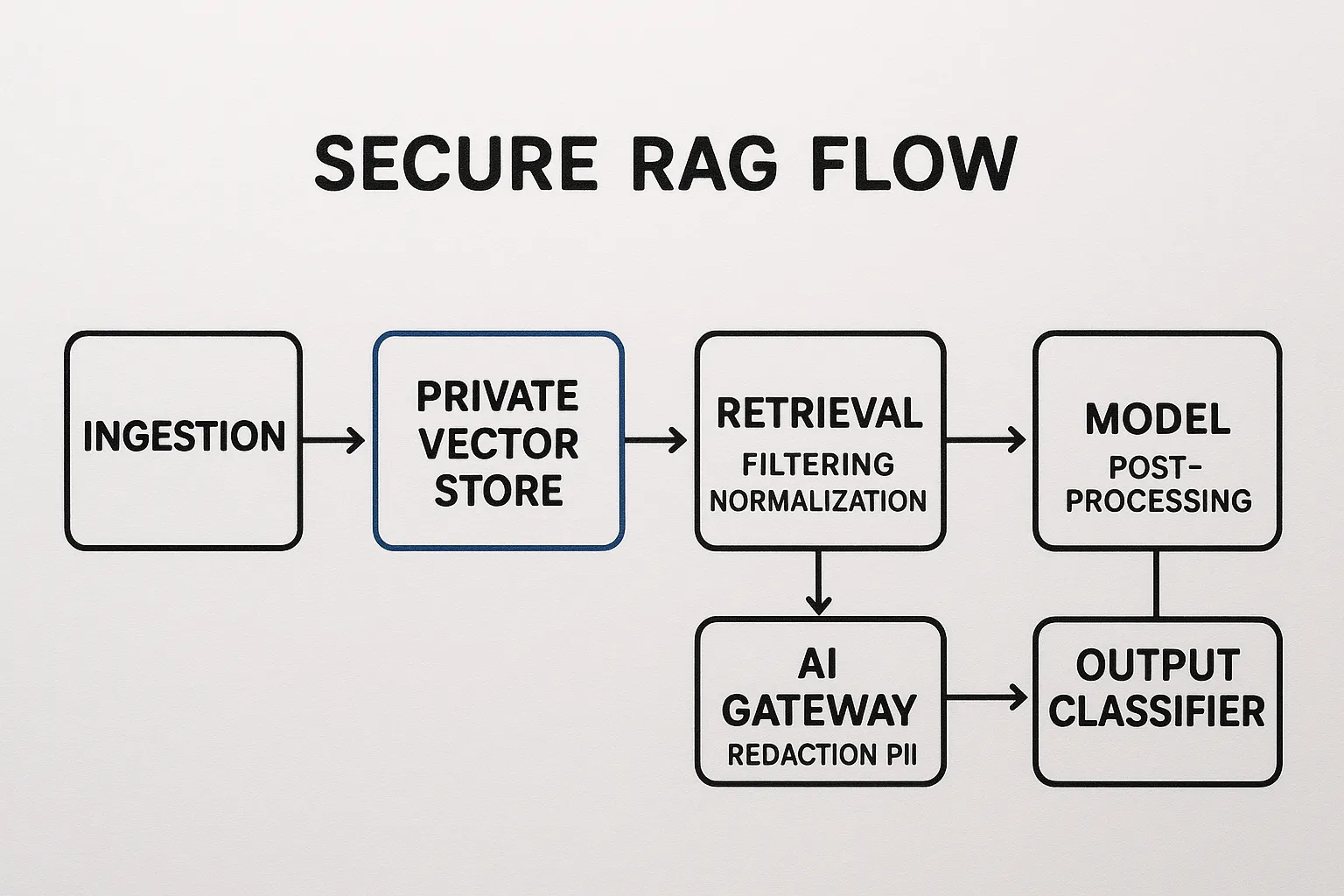
4. RAG orchestré (retrieve then generate)
Connaissance interne, bases documentaires
Réponses contextualisées, mise à jour continue
Injection via documents, fuite d’index
Sanitize du contexte, signaux de confiance, contrôle des sources
5. Function calling et outils contrôlés
Agents opérationnels, actions métiers déléguées
Ces modèles ne s’excluent pas. Beaucoup d’équipes combinent une passerelle AI interne avec RAG pour la connaissance et du batch pour les traitements de fond.
Principes d’architecture « propre » pour les API AI
Séparer l’orchestration de l’application. Centralisez prompts, politiques, tests et métriques dans une couche dédiée, plutôt que de disperser la logique dans chaque service.
Contrats stables. Définissez des schémas stricts d’entrée et de sortie (JSON Schema). Gérez la version via /v1, /v2, avec dépréciation et migration planifiée.
Gestion de prompts industrielle. Templating, variables typées, tests de régression sur un set d’exemples. Versionnez prompts et paramètres par cas d’usage.
Idempotence et réessais. Les appels AI échouent parfois, planifiez des retries avec backoff et des clés d’idempotence pour éviter les duplications.
Coûts sous contrôle. Budgets par produit, plafonds de tokens, mise en cache déterministe des résultats stables, alertes sur dérive de consommation.
Observabilité de bout en bout. Traces distribuées, corrélation demande, prompt, contexte RAG, sortie et coût. Filtrage des PII dans les logs.
Pour la télémétrie, standardisez vos traces avec OpenTelemetry, puis agrégerez dans votre stack d’observabilité préférée. Référence: OpenTelemetry.
Sécurité et conformité by design
Secrets et identités machines. Stockez les clés fournisseurs dans un KMS ou un coffre. Rotation régulière, accès par rôle, jamais en variable d’environnement partagée.
Authentification et autorisation. Machine-to-machine via OAuth2 client credentials, scopes minimaux, politique par service au niveau de votre passerelle.
Protection des données. Chiffrement en transit et au repos, minimisation stricte des champs envoyés, pseudonymisation lorsque possible. La CNIL détaille la pseudonymisation ici: CNIL, la pseudonymisation.
Journalisation sûre. Jamais de prompts bruts contenant PII en clair dans les logs. Redaction automatique avant stockage.
Défense contre les menaces LLM. Gérez la prompt injection, overreliance et exfiltration de données selon l’OWASP Top 10 for LLM Applications.
Sécurité API classique. N’oubliez pas les fondamentaux de l’OWASP API Security Top 10: contrôle d’accès, rate limit, validation stricte des entrées.
Gouvernance et conformité. Catégorisez les données, documentez les flux, choisissez la région de traitement adaptée, renseignez les durées de conservation, établissez les bases légales. La CNIL synthétise les enjeux IA et RGPD ici: IA et RGPD, CNIL. Côté gestion du risque, appuyez-vous sur le NIST AI RMF. Sur l’AI Act, suivez le calendrier d’application et la classification des risques sur la page officielle de la Commission: European AI Act.
Patterns d’implémentation recommandés
Passerelle AI avec politiques centralisées
Un point d’entrée unique pour tous les appels AI.
Politique par client ou produit: modèles autorisés, budgets, régions, redaction PII.
Journaux structurés, traçabilité, A/B testing et fallback multi-fournisseurs.
Exemple minimal en Python, pour illustrer les garde-fous essentiels:
from fastapi import FastAPI, Header, HTTPException
import httpx, time
app = FastAPI()
ALLOWED_MODELS = {"gpt-4o", "claude-3-5-sonnet"}
BUDGET_TOKENS = {"appA": 2_000_000}
async def redact_pii(text: str) -> str:
# Remplacez par une vraie détection PII
return text.replace("@", " [at] ")
@app.post("/ai/generate")
async def generate(payload: dict, x_client_id: str = Header("")):
if x_client_id not in BUDGET_TOKENS:
raise HTTPException(403, "client inconnu")
model = payload.get("model")
if model not in ALLOWED_MODELS:
raise HTTPException(400, "modèle non autorisé")
prompt = await redact_pii(payload.get("prompt", ""))
try:
async with httpx.AsyncClient(timeout=30) as client:
resp = await client.post(
"https://provider.example.com/v1/chat",
json={"model": model, "input": prompt},
headers={"Authorization": "Bearer <secret-from-kms>"}
)
resp.raise_for_status()
except httpx.HTTPError:
# Fallback basique, journalisez et appliquez un circuit breaker en prod
raise HTTPException(502, "fournisseur indisponible")
data = resp.json()
# Décrémentez le budget en fonction des tokens consommés
BUDGET_TOKENS[x_client_id] -= data.get("usage", {}).get("total_tokens", 0)
return {"output": data.get("output"), "usage": data.get("usage"), "ts": int(time.time())}
RAG sécurisé et contrôlé
Index privé, séparation stricte entre données sources et contexte envoyé au modèle.
Normalisation du contexte, suppression du HTML/script, ajout de métadonnées de provenance.
Filtre de sécurité sur le contexte avant appel au modèle, et classifieur de sortie.
Function calling sans prise de risque
Liste blanche des fonctions et des paramètres, schémas stricts.
Sandboxes pour toute action à effets externes.
Confirmer côté humain pour les opérations sensibles (paiement, suppression, escalade de privilèges).
Observabilité, qualité et coûts
Traces et corrélation. Tracez chaque requête avec un ID de corrélation, du front au fournisseur. Conservez prompt, contexte et réponse sous forme masquée si nécessaire.
Évaluation continue. Constituez un jeu de tests représentatif, exécutez-le à chaque changement de prompt, de modèle ou de température. Suivez des métriques de qualité métier (exactitude de champs extraits, taux de refus corrects, temps de réponse).
Coûts prévisibles. Budgets par produit, alertes sur dépassement, cache pour demandes fréquentes. Utilisez des stratégies de streaming et de truncation pour limiter les tokens.
Checklists rapides
Avant d’envoyer la première requête
Inventaire des données et classification par sensibilité.
Base légale de traitement, consentement si nécessaire, régions de traitement documentées.
Décision explicite sur l’option d’entraînement du fournisseur à partir de vos données, si disponible.
Coffre à secrets et rôles de service configurés, clés non stockées dans le code.
Journalisation et traçabilité prêtes, avec redaction PII.
Pendant l’intégration
Pattern d’intégration choisi, justifié et documenté.
Politique de modèles autorisés, timeout, retry et circuit breaker.
Tests de prompts, cas limites, jeux d’évaluation versionnés.
Contrôles anti-injection sur le contexte RAG et classifieur de sortie.
Avant mise en prod
Revue sécurité et conformité, DPIA si nécessaire.
Tests de charge, budget de tokens, latence et plan de dégradation.
Runbooks d’incident, rotation de clés et procédure de révocation.
Plan d’exécution sur 30 jours
Semaine 1, cadrage et conformité. Cartographiez les flux de données, choisissez le modèle d’intégration, rédigez le registre RGPD et évaluez le risque avec le NIST AI RMF. Décidez des régions de traitement et de la politique de rétention.
Semaine 2, plateforme et garde-fous. Déployez la passerelle AI, configurez secrets, rate limiting, masquage PII, traces. Mettez en place un index RAG si nécessaire, avec pipeline d’ingestion sécurisé.
Semaine 3, qualité et sécurité LLM. Constituez vos jeux d’évaluation, automatisez les tests, implémentez les garde-fous anti-injection et le classifieur de sortie. Ajoutez modèles de secours et stratégie de fallback.
Semaine 4, durcissement et go-live. Tests de charge, chaos et coupure fournisseur simulée. Revue de conformité finale, runbooks d’incident, alertes coûts et qualité, formation des équipes.
Erreurs fréquentes à éviter
Intégrer côté client avec une clé longue durée exposée dans le code.
Logger les prompts bruts contenant e-mails, identifiants ou numéros de dossier.
Mélanger logique de prompt et règles de sécurité dans chaque microservice au lieu de centraliser.
Laisser les modèles choisir librement les actions sans liste blanche ni sandbox.
Oublier la migration de versions, ce qui fige un modèle et bloque l’évolution.
FAQ
Les fournisseurs d’API AI entraînent-ils leurs modèles avec mes données par défaut? Cela dépend du fournisseur et du plan. Vérifiez la politique d’utilisation des données, désactivez l’apprentissage sur vos contenus si c’est possible et formalisez cette décision dans votre registre de traitements.
Peut-on appeler une API AI directement depuis une application front? Évitez pour tout cas réel. Si vous devez prototyper, passez par des jetons éphémères ultra restreints générés par votre backend et limitez les fonctionnalités exposées.
Comment se prémunir des attaques de prompt injection? Nettoyez et normalisez tout contexte injecté, ajoutez des instructions de sécurité, limitez les outils disponibles, utilisez un classifieur de sortie et surveillez en production. Appuyez-vous sur l’OWASP Top 10 LLM pour les menaces spécifiques.
Que faire des PII dans les prompts? Minimisez et pseudonymisez dès la source. Filtrez et masquez dans les logs. La CNIL fournit des repères pratiques sur la pseudonymisation.
RAG ou fine-tuning pour incorporer ma connaissance? Commencez par RAG, plus rapide et gouvernable. Le fine-tuning arrive ensuite pour des gains spécifiques, en maîtrisant bien les jeux de données et les risques de fuite.
Prêt à intégrer des API AI sans compromis sur la sécurité et la qualité? Impulse Lab accompagne les équipes produit et IT de bout en bout, de l’audit d’opportunités AI à l’intégration et à la formation. Nous livrons chaque semaine, impliquons vos équipes tout au long du projet et centralisons le suivi dans un portail client dédié. Parlez-nous de votre contexte et sécurisons votre feuille de route AI: https://impulselab.ai