HTTPS AI : sécuriser vos appels API et données sensibles
Intelligence artificielle
Stratégie IA
Confidentialité des données
Gouvernance IA
Gestion des risques IA
Quand une équipe “branche” une API d’IA (LLM, vision, transcription, scoring, etc.), elle fait souvent deux choses en même temps : elle ouvre un flux de données vers un tiers, et elle met en production un nouveau point d’entrée technique. Dans beaucoup de PME et scale-ups, la première barrière de sé...
Quand une équipe “branche” une API d’IA (LLM, vision, transcription, scoring, etc.), elle fait souvent deux choses en même temps : elle ouvre un flux de données vers un tiers, et elle met en production un nouveau point d’entrée technique. Dans beaucoup de PME et scale-ups, la première barrière de sécurité qui vient à l’esprit est simple : “on est en HTTPS, donc c’est bon”.
C’est un bon début. Mais HTTPS n’est qu’une couche. Pour sécuriser des appels API d’IA et des données sensibles, il faut aussi traiter la gestion des secrets, l’authentification, la minimisation des données, les logs, et les garde-fous d’intégration.
“HTTPS AI”, ça veut dire quoi en pratique ?
Le terme HTTPS AI n’est pas un standard officiel. Dans les faits, il renvoie le plus souvent à ce besoin : sécuriser des appels HTTP(S) vers des services d’IA (internes ou externes), et protéger les données qui transitent dans ces requêtes.
En 2026, ce sujet est devenu central pour trois raisons :
Les flux IA manipulent plus souvent des données sensibles (tickets support, documents, extraits CRM, contrats, emails).
Les usages “copilot” et “agent” multiplient les intégrations (CRM, helpdesk, ERP, Slack/Teams, drive documentaire) et donc les surfaces d’attaque.
Les exigences de conformité (RGPD, AI Act selon les cas d’usage) rendent la traçabilité et la gouvernance plus importantes.
Ce que HTTPS protège (et ce qu’il ne protège pas)
HTTPS, c’est HTTP sur TLS. Concrètement, TLS vise trois propriétés essentielles :
Confidentialité : le contenu est chiffré “en transit”.
Intégrité : on évite la modification discrète des messages.
Authentification du serveur : via les certificats, le client peut vérifier qu’il parle au bon service (si la chaîne de confiance est valide).
En revanche, HTTPS ne protège pas :
Le fait d’envoyer “trop de données” (par exemple un email complet contenant des informations inutiles).
Les fuites par logs, exports, outils d’observabilité, ou environnements de debug.
Une clé API exposée dans un navigateur, dans un dépôt Git, ou dans un outil no-code.
Les erreurs d’autorisation (droits trop larges), les mauvais scopes, ou l’absence de séparation des environnements.
Pour cadrer le sujet, un repère utile est l’OWASP API Security Top 10 (les problèmes réels viennent souvent plus de l’auth, du contrôle d’accès et de la mauvaise hygiène que de TLS).
Menaces typiques sur des appels API d’IA
Sans tomber dans le parano, voici les scénarios les plus fréquents rencontrés en production :
1) Clés API exposées
Une clé API côté front (JS), dans un mobile, ou dans un outil d’automatisation mal configuré peut être copiée et utilisée pour :
Exfiltrer des données (si l’API permet de relire des artefacts).
Générer des coûts importants.
Contourner des garde-fous (si vous avez plusieurs modèles ou routes).
2) Données sensibles qui “partent” sans contrôle
Exemples classiques :
Un assistant interne qui envoie des données RH ou des données clients au fournisseur d’IA alors qu’un résumé ou des champs anonymisés suffisaient.
Des pièces jointes ou documents ingérés sans filtrage (contrats, factures, exports CRM).
3) Fuites via logs et observabilité
On veut monitorer la qualité et les coûts, donc on loggue. Mais si on loggue les prompts bruts, les réponses brutes, ou des pièces jointes, on crée un “data lake” involontaire.
4) Attaques d’interception ou de redirection (moins fréquentes, mais réelles)
Même avec HTTPS, certains risques existent si la configuration est faible (downgrade TLS), si le DNS est compromis, ou si des certificats sont mal gérés.
Checklist “HTTPS AI” : sécuriser vos appels API et données sensibles
L’objectif ici est pragmatique : réduire le risque sans ralentir la delivery.
1) Forcer HTTPS partout, et éliminer les configurations faibles
Points d’attention simples, mais souvent oubliés :
Bloquer HTTP (redirection vers HTTPS, pas d’endpoint “oublié”).
Activer HSTS (côté web) pour éviter les accès accidentels en HTTP.
Limiter TLS aux versions modernes (TLS 1.2 minimum, TLS 1.3 si possible).
Renouvellement des certificats automatisé et surveillé.
Contrôle rapide : utilisez un test de configuration TLS public, par exemple SSL Labs (Qualys) sur vos endpoints exposés.
2) Ne jamais appeler une API d’IA directement depuis le navigateur (sauf cas contrôlé)
Dans une PME, c’est une source majeure de fuite de secrets.
Bon principe : les appels au fournisseur d’IA passent par votre back-end (ou une passerelle interne), et le front appelle uniquement votre API.
Exception possible : des scénarios avec jetons éphémères limités, générés côté serveur, avec scopes stricts et durée de vie courte. C’est une architecture à concevoir explicitement, pas un “raccourci”.
3) Authentifier et autoriser correctement vos appels internes
HTTPS chiffre, mais ne décide pas “qui a le droit”. Sur des plateformes qui se structurent, les erreurs viennent souvent du contrôle d’accès.
Authentification user ou service-to-service cohérente.
Scopes et rôles (least privilege).
Séparation stricte des environnements (dev, staging, prod).
Si vous voulez un rappel des notions et protocoles (OAuth2, OIDC, etc.), la fiche lexique Impulse Lab peut aider : Authentification.
4) Gestion des secrets (API keys, tokens, certificats)
Un standard minimal pour PME et scale-ups :
Secrets dans un secret manager ou au minimum des variables d’environnement injectées au runtime.
Rotation planifiée (et procédure de révocation).
Aucune clé dans le code, les tickets, les docs, ou les outils de chat.
Même si votre transport est parfait (TLS), une clé compromise annule tout.
5) Minimisation et classification des données (le vrai “pare-feu” IA)
Avant d’envoyer une donnée à une API d’IA, posez une question simple : “De quoi l’IA a réellement besoin pour produire la bonne sortie ?”
Bonnes pratiques concrètes :
Classer vos données (publique, interne, confidentielle, sensible) avec une règle simple.
Remplacer les identifiants directs (nom, email, tel) par des pseudonymes lorsque possible.
Envoyer des extraits plutôt que des documents complets.
Séparer les tâches “rédaction” des tâches “vérité” (quand la réponse doit être factuelle, s’appuyer sur une source interne contrôlée).
Pour les enjeux RGPD côté usage d’outils et d’IA, la CNIL publie des repères utiles (et c’est souvent un bon point de départ pour cadrer minimisation et finalité).
6) Redaction (masquage) avant l’appel, et politique de logs “safe by default”
Deux règles qui évitent 80% des incidents :
Masquer ce qui n’est pas nécessaire (PII, numéros, IBAN, identifiants, etc.) avant l’envoi.
Logger d’abord des métadonnées, pas le contenu complet.
Exemples de métadonnées utiles : latence, taille des prompts, route utilisée, coût estimé, taux d’erreur, identifiant de requête, et éventuellement un hash du contenu.
7) Limites, throttling, et protection contre les abus
Même en interne, un bug ou un agent peut déclencher des boucles d’appels.
Rate limiting par utilisateur et par service.
Quotas par environnement.
Timeouts stricts, retries contrôlés.
Idempotence quand c’est applicable.
8) Tests de sécurité et validation continue
En IA, il est tentant de ne tester que “la qualité”. Il faut aussi tester :
Les chemins d’erreur.
Les logs.
Les accès.
Les comportements en surcharge.
Côté références, l’ANSSI est une ressource utile en France pour la culture de base sécurité (hygiène, gestion des risques, recommandations générales).
Tableau récapitulatif : risques courants et contrôles rapides
Risque
Exemple
Mesure de mitigation
Contrôle simple
Clé API exposée
Clé dans le front ou un dépôt
Appels via back-end, secret manager, rotation
Scan de repo, revue CI, audit des apps no-code
Données trop riches envoyées
Ticket support complet + PII
Minimisation, pseudonymisation, redaction
Revue d’échantillons de prompts en staging
Logs “toxiques”
Prompts/réponses en clair dans l’observabilité
Politique de logs, redaction, rétention courte
Audit des dashboards et exports
Mauvais contrôle d’accès
Tout le monde peut lancer une action “agent”
RBAC, scopes, approbation humaine
Tests d’autorisation, revues de rôles
Downgrade / mauvaise config TLS
Endpoint legacy encore en HTTP
HSTS, TLS min 1.2, redirection
SSL Labs + inventaire endpoints
Abus / boucle d’appels
Agent qui s’emballe
Rate limiting, quotas, timeouts
Tests de charge et scénarios d’échec
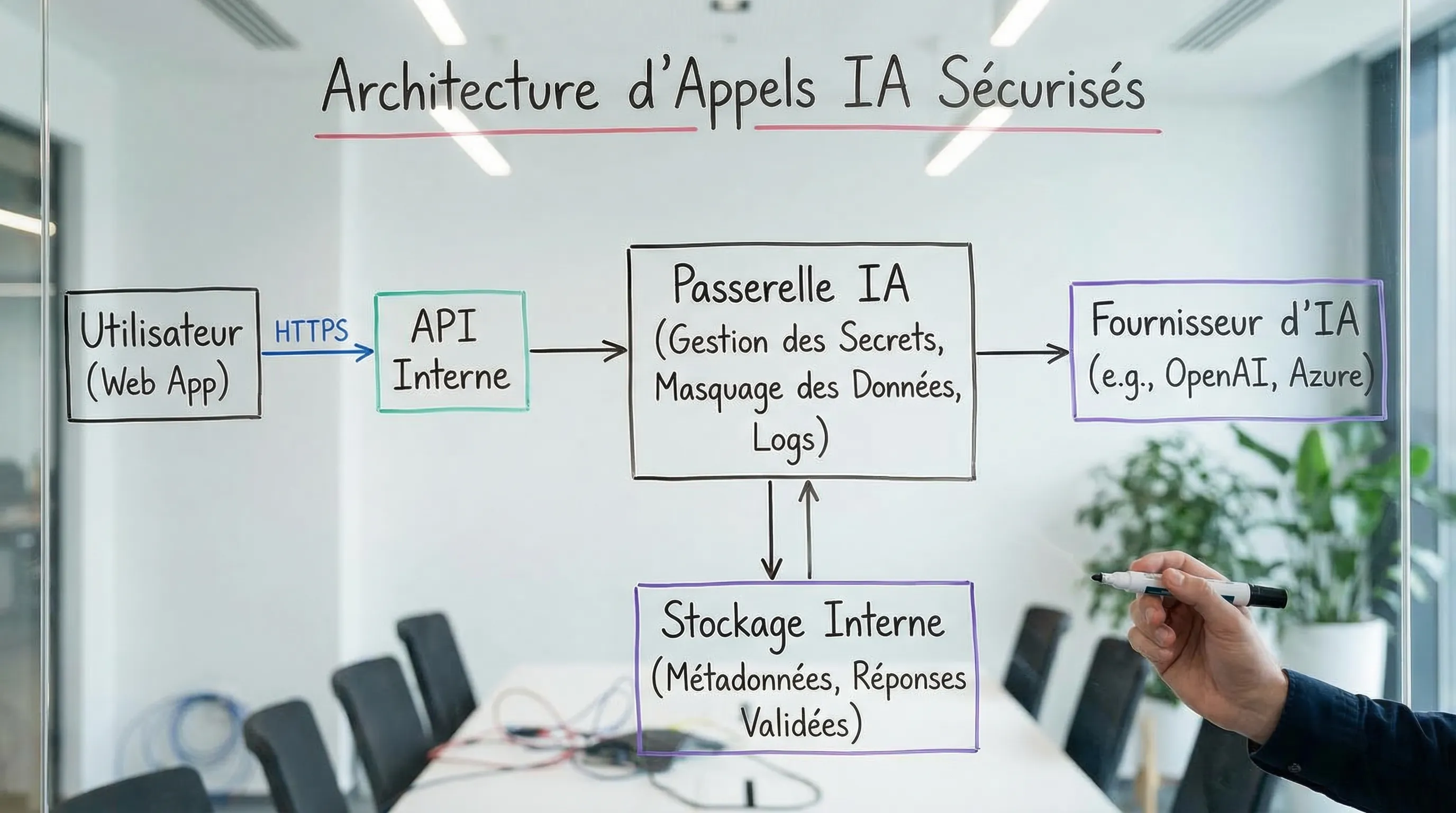
Architecture recommandée : passerelle IA (AI gateway) et séparation des responsabilités
Pour sécuriser “HTTPS AI” au-delà du transport, une architecture robuste consiste à centraliser les appels IA dans une couche dédiée (back-end ou passerelle). Cette couche gère :
Les secrets (jamais dans le client)
La redaction / minimisation
Les logs safe
Les quotas
Les routes (modèles, providers) et le fallback
Un bon test mental : si vous devez changer de fournisseur IA demain, vous voulez que le changement soit principalement dans cette couche, sans toucher toutes les apps.
Exemple concret : assistant support, données client et appels API
Imaginez un assistant qui aide à répondre aux tickets.
Flux recommandé :
Le conseiller ouvre un ticket dans votre outil.
Votre back-end récupère les champs nécessaires (problème, produit, historique utile).
Une étape de redaction retire ou pseudonymise les données inutiles.
L’appel API IA part via HTTPS vers le fournisseur.
La réponse revient, puis votre système :
Ajoute des citations ou références internes si vous utilisez un RAG.
Enregistre la réponse proposée.
Loggue seulement les métriques nécessaires (coût, latence, route, statut), pas le contenu brut.
Le point important : HTTPS protège le trajet, mais la sécurité réelle vient du fait que vous contrôlez ce qui sort, ce qui est conservé, et qui peut déclencher l’action.
Quand aller au-delà de HTTPS (mTLS, réseaux privés, self-host)
Selon votre contexte (données très sensibles, secteur régulé, exigences client), vous pouvez renforcer la couche transport et réseau :
mTLS (authentification mutuelle) pour des communications service-to-service critiques.
Connectivité privée (selon les options de vos fournisseurs et votre infra).
Approches hybrides, voire modèles auto-hébergés pour certains traitements.
Ce sont des choix d’architecture et de coûts. Ils ne remplacent pas la minimisation, la gestion des secrets et une politique de logs propre.
Frequently Asked Questions
HTTPS suffit-il pour protéger mes données quand j’utilise une API d’IA ? HTTPS est nécessaire (chiffrement en transit), mais insuffisant. Les fuites viennent souvent des clés API, des logs, d’un excès de données envoyées, ou d’autorisations trop larges.
Dois-je appeler l’API d’IA depuis mon front-end (JavaScript) ? En général, non. Cela expose vos secrets. Préférez un appel via back-end ou une passerelle IA, avec éventuellement des jetons éphémères très limités si vous avez un cas précis.
Quelles données ne faut-il jamais envoyer à une IA ? Tout dépend de votre politique et de votre base légale, mais par défaut, minimisez : identifiants directs, données bancaires, données de santé, informations RH sensibles, secrets commerciaux. Envoyez uniquement ce qui est indispensable.
Comment éviter que mes prompts et réponses finissent dans les logs ? Définissez une politique de logs (métadonnées plutôt que contenu), appliquez de la redaction, et contrôlez la rétention et les exports de vos outils d’observabilité.
TLS 1.3 est-il obligatoire pour “HTTPS AI” ? Non, mais TLS 1.2 minimum est un bon standard. L’essentiel est d’éviter HTTP, les suites faibles, et de maintenir correctement certificats et configurations.
Par quoi commencer si je soupçonne que mon intégration IA n’est pas assez sécurisée ? Faites un inventaire des endpoints, des flux de données, des secrets, et des logs. Ensuite, corrigez les points à fort risque (clés exposées, données trop riches, absence de RBAC) avant d’optimiser la qualité des réponses.
Passer de “on est en HTTPS” à “on est vraiment en sécurité”
Si vous déployez (ou allez déployer) des appels API d’IA dans vos processus, le bon réflexe est de traiter la sécurité comme un sujet d’architecture et de gouvernance, pas comme un simple paramètre réseau.
Impulse Lab accompagne les PME et scale-ups sur ces sujets via :
Des audits d’opportunités et de risques IA (prioriser les bons cas, définir les garde-fous)
Le développement et l’intégration de solutions IA (API, automatisations, plateformes)
La formation à l’adoption (règles d’équipe, bonnes pratiques data et sécurité)
Pour cadrer rapidement vos flux et éviter les erreurs coûteuses, vous pouvez démarrer par un contenu connexe, puis nous contacter :
IA travail : 10 tâches à déléguer sans perdre la main
L’IA au travail est utile quand elle enlève de la friction, pas quand elle remplace le jugement métier. Pour une PME, une scale-up ou une équipe en structuration, la bonne question n’est donc pas “qu’est-ce que l’IA peut faire à ma place ?”, mais plutôt : “quelles tâches puis-je lui déléguer pour ré...