Meilleure agence IA Paris : comment comparer sans biais
Intelligence artificielle
Stratégie d'entreprise
Stratégie IA
ROI
Automatisation
Choisir la **meilleure agence IA à Paris** ressemble souvent à un concours de pitchs. Démos impressionnantes, logos prestigieux, promesses de “ROI en 2 semaines”… puis, six mois plus tard, un POC qui ne passe jamais en production parce que les données sont bancales, l’intégration est trop chère, ou...
Choisir la meilleure agence IA à Paris ressemble souvent à un concours de pitchs. Démos impressionnantes, logos prestigieux, promesses de “ROI en 2 semaines”… puis, six mois plus tard, un POC qui ne passe jamais en production parce que les données sont bancales, l’intégration est trop chère, ou la gouvernance n’a pas été pensée.
L’objectif de cet article n’est pas de vous dire quelle agence est “la meilleure” en absolu, mais de vous donner une méthode comparative, reproductible et sans biais, adaptée aux PME et scale-ups qui veulent structurer leur adoption de l’IA (automatisation, assistants, agents, RAG, intégrations) avec des résultats mesurables.
Pourquoi “meilleure agence IA Paris” est une mauvaise question (et comment la remplacer)
Le mot “meilleure” mélange trois sujets différents.
La compétence technique (architecture, sécurité, qualité logicielle, évaluation des modèles).
La compétence produit (capacité à cadrer un cas d’usage, définir un KPI, livrer une V1 utile, itérer).
La compatibilité d’exécution (votre stack, vos contraintes, votre rythme, votre niveau de maturité data, votre organisation).
La bonne question devient donc : “Quelle agence IA à Paris est la meilleure pour notre cas d’usage, avec nos contraintes, et un chemin clair vers la production ?”
Pour y répondre sans biais, il faut comparer sur des preuves, pas sur des impressions.
Les biais les plus fréquents quand on compare une agence IA (et comment les neutraliser)
Une sélection est rarement “rationnelle”. Elle est influencée par des biais cognitifs très classiques, et l’IA les amplifie parce que la démo peut être spectaculaire.
Biais 1 : le biais de démonstration (“wow effect”)
Une démo fluide masque souvent ce qui coûte cher : ingestion des données, droits d’accès, logs, tests, run en production, support.
Antidote : demandez une démo sur vos données ou, a minima, sur un corpus représentatif anonymisé, avec un protocole de test.
Biais 2 : le biais de marque (logos, “références”, présence médiatique)
Une grande marque peut être pertinente, ou totalement surdimensionnée pour une PME (coût, lourdeur, priorisation).
Antidote : comparez à périmètre égal (même livrable, même délai, mêmes contraintes de sécurité, même niveau d’intégration).
Biais 3 : le biais d’autorité technique
Un discours très pointu (LLMOps, agents, MCP, multi-modèle) peut donner confiance, sans prouver la capacité à livrer.
Antidote : exigez des artefacts concrets (exemples de runbook, scorecards, plans de test, schémas d’architecture) plutôt qu’un discours.
Biais 4 : l’ancrage sur le prix
Le premier devis sert d’ancre, et tout le reste est “cher” ou “pas cher” sans être relié à la valeur.
Antidote : comparez au TCO (coût total) sur 6 à 12 mois : build, intégrations, licences/API, monitoring, maintenance RAG, formation, conformité.
Biais 5 : le biais “outil d’abord”
Certaines agences vendent une stack avant de cadrer le besoin, ou poussent un outil parce qu’elles sont partenaires.
Antidote : commencez par un KPI et une contrainte (données, RGPD, latence, budget), puis seulement ensuite discutez la solution.
Biais 6 : le biais de proximité
“Ils sont à Paris, on peut se voir, donc ça va marcher.” La proximité aide, mais ne remplace pas une méthode.
Antidote : formalisez un cadre d’exécution (rituels, jalons, responsabilités, critères de sortie du pilote).
Biais 7 : le biais de confirmation
Vous avez déjà une préférence, et vous cherchez des éléments qui la confirment.
Antidote : utilisez une grille de scoring avant les rendez-vous, puis mettez-la à jour après, pas l’inverse.
Les preuves à demander (plutôt que des promesses)
Pour comparer sans biais, demandez des éléments vérifiables. Une agence sérieuse ne doit pas tout “ouvrir”, mais doit pouvoir montrer des exemples anonymisés et expliciter ses standards.
Ce que vous devez vérifier
Preuve attendue
Comment éviter l’illusion
Capacité à cadrer la valeur
Exemple de cadrage (objectif, périmètre, KPI, baseline)
Sur la conformité, vous pouvez aussi exiger que le prestataire soit capable de discuter les implications du RGPD et du cadre européen (notamment l’AI Act de l’UE). Pour la gestion des risques, le référentiel NIST AI RMF sert souvent de base pragmatique.
Une grille de scoring simple (utilisable en interne, même sans expert IA)
Vous n’avez pas besoin d’un modèle compliqué. Une bonne scorecard doit être courte, partagée, et liée à votre réalité.
Critère
Poids recommandé
Exemple de question de vérification
Compréhension du cas d’usage et du KPI
20%
“Quelle est la baseline et quel gain réaliste en 30 jours ?”
Intégration (stack, données, outils)
20%
“Quelles intégrations minimales pour une V1 utile ?”
Sécurité, RGPD, gouvernance
15%
“Quelles données sortent, où, combien de temps, avec quelles traces ?”
Méthode de delivery (cadence, itérations)
15%
“Quels livrables hebdo, et comment on décide go/no-go ?”
Fiabilité (tests, évaluation, monitoring)
15%
“Quel protocole de test avant pilote, puis en continu ?”
Coût total (6-12 mois) et maîtrise des variables
10%
“Quels coûts récurrents et quels plafonds ?”
Transfert de compétences (adoption)
5%
“Quel plan de formation au point d’usage ?”
Conseil pratique : faites scorer au moins deux personnes (métier + tech/ops). Les divergences sont souvent plus instructives que la moyenne.
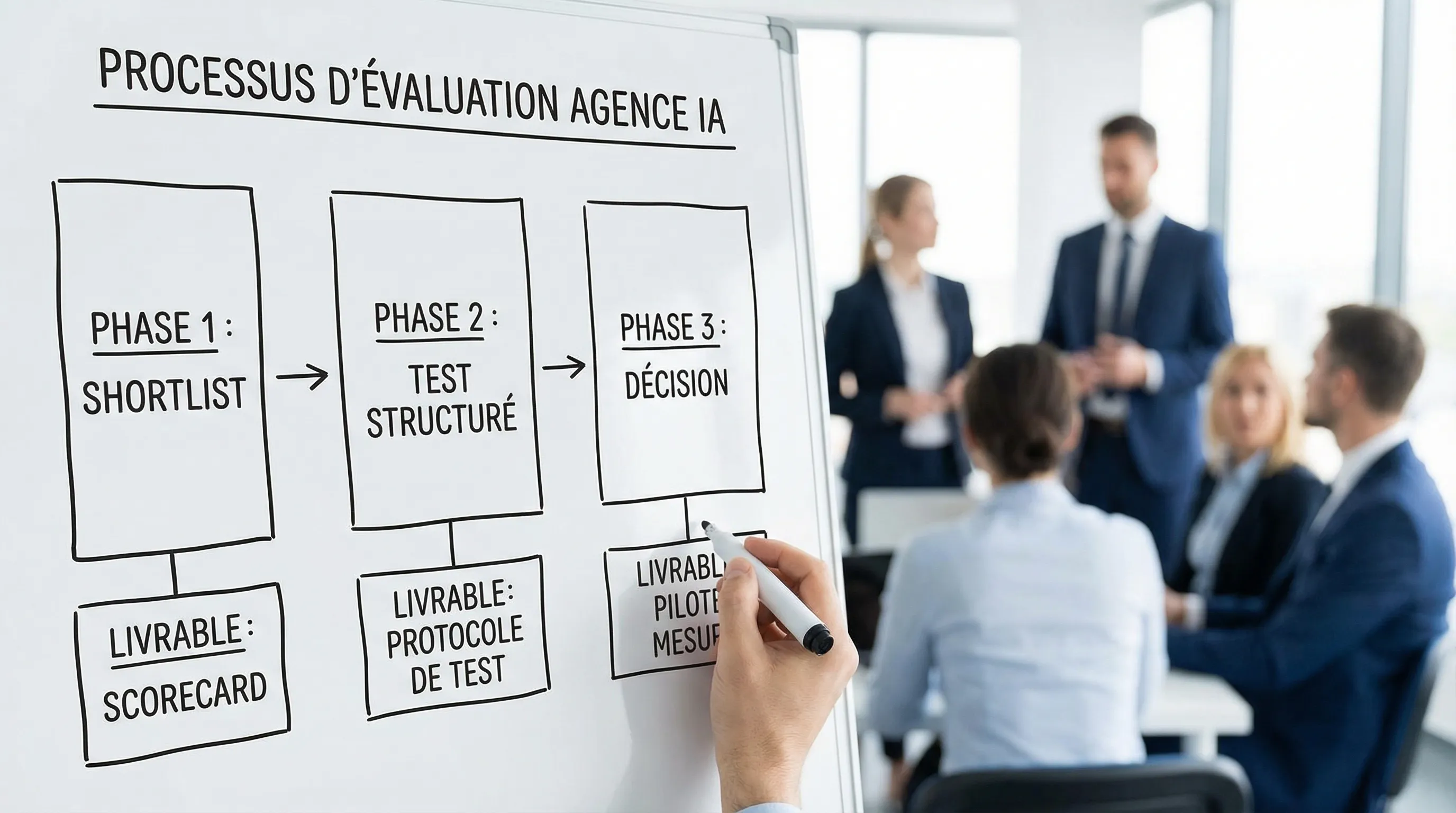
Un protocole “sans biais” en 10 jours pour comparer 3 agences (sans y passer 2 mois)
L’erreur classique est de faire 6 rendez-vous de 45 minutes et de choisir “au feeling”. À la place, mettez tout le monde dans le même entonnoir.
Jour 1 : cadrage interne (30 à 60 minutes)
Fixez :
1 cas d’usage prioritaire (pas 5)
1 KPI North Star (temps, taux de résolution, marge, conversion)
2 contraintes non négociables (données sensibles, hébergement, SSO, budget)
Si vous n’avez pas ce cadrage, un audit d’opportunités est souvent l’étape la plus rentable, parce qu’il évite de partir sur le mauvais projet (Impulse Lab détaille ce format dans son article sur l’audit IA stratégique).
Jour 2 : mini-brief identique envoyé aux agences
Un document d’une page suffit : contexte, cas d’usage, KPI, stack, contraintes, deadline.
Jours 3 à 5 : “atelier de comparaison” (60 minutes par agence)
Même agenda pour tous :
reformulation du besoin
proposition d’approche V1 (périmètre minimal)
risques et garde-fous
estimation TCO et planning
Jour 6 : test structuré (asynchrone)
Donnez le même pack à chaque agence : 10 à 20 exemples réels (anonymisés), une règle de sécurité, et une consigne.
Le but n’est pas d’obtenir une app finie, mais d’évaluer : qualité, transparence, méthode, rigueur.
Jours 7 à 8 : lecture des livrables et scoring
Vous scorez à froid, puis vous préparez 5 questions “bloquantes” par agence.
Jour 9 : call de clarification (30 minutes)
Uniquement sur les points flous. Pas de re-pitch.
Jour 10 : décision et cadrage du pilote
Vous choisissez et vous contractualisez un pilote mesuré, avec critères de sortie.
Les questions qui révèlent vite la maturité d’une agence IA
Vous n’avez pas besoin d’une liste interminable. Quelques questions “qui piquent” suffisent à distinguer une équipe orientée production d’une équipe orientée démonstration.
Mesure : “Quel KPI exact, comment on le mesure, et à quelle fréquence on fait le point ?”
Données : “Quelles données sont nécessaires, qui en est owner, et quel plan si elles sont incomplètes ?”
Intégration : “Dans quel outil l’utilisateur voit le résultat (CRM, helpdesk, Slack, app interne) ?”
Fiabilité : “Quel est votre protocole de test (scénarios, golden set), avant et après mise en prod ?”
Sécurité : “Quelles protections contre l’exfiltration, la prompt injection, les fuites PII ?”
Adoption : “Qui est formé, quand, et comment on évite que l’outil soit abandonné à J+30 ?”
Sur la partie intégration et architecture, un bon signal est la capacité à parler “proprement” des modèles d’intégration (API, passerelle IA, RAG, tool-calling). Si vous voulez approfondir, le guide d’Impulse Lab sur les modèles d’intégration d’API IA donne un vocabulaire utile pour challenger un prestataire.
Les signaux d’alerte (spécifiques à l’IA générative en 2026)
Certains signaux doivent vous faire ralentir, même si l’équipe est sympathique et la démo convaincante.
“On va tout faire avec un agent autonome” dès la V1
Les agents sont puissants, mais ils demandent plus de garde-fous (actions, idempotence, droits, logs). Commencer trop “agentic” augmente le risque.
Absence de stratégie RAG ou de gestion de la vérité
Si l’agence ne sait pas expliquer comment elle limite les hallucinations (sources, RAG, contraintes, vérification), vous achetez du risque.
Pas de plan d’observabilité
Sans logs et métriques, vous ne pilotez ni la qualité, ni les coûts, ni la conformité.
Confusion entre usage et impact
“Les équipes aiment l’outil” n’est pas un KPI business. Une agence orientée valeur vous parlera de baseline et d’impact.
(À ce sujet, vous pouvez vous appuyer sur un cadre de mesure type, comme celui décrit dans l’article Impulse Lab sur les KPIs IA même si la page est en anglais.)
Paris : vrai avantage ou faux critère ?
À Paris, l’offre est abondante (agences web qui “font de l’IA”, cabinets de conseil, studios data, freelances, intégrateurs). La localisation peut aider pour :
ateliers de cadrage avec des équipes mixtes
conduite du changement (formation, adoption)
gouvernance (juridique, DPO, RSSI)
Mais dans 80% des cas, ce n’est pas la variable qui fait réussir un projet. Ce qui compte est la capacité à livrer vite une V1 intégrée, mesurée, sécurisée, puis à itérer.
Ce que vous devriez obtenir avant de signer (pour réduire le risque)
Avant de lancer une mission, assurez-vous que le “pack de départ” existe. C’est souvent là que se cache la différence entre une agence IA qui prototype et une agence IA qui industrialise.
Élément
Pourquoi c’est critique
Périmètre V1 et exclusions explicites
Évite l’explosion de scope
KPI + baseline + méthode de mesure
Évite les projets non prouvables
Architecture cible (même simple)
Évite les refontes tardives
Règles data (classification, rétention)
Évite les risques RGPD
Protocole de test + critères d’acceptation
Évite la “qualité subjective”
Ownership et runbook minimal
Évite l’abandon après livraison
Et si vous voulez comparer plus vite : la règle “audit court, pilote mesuré”
Quand l’incertitude est élevée (données, risques, choix entre build et buy), la stratégie la plus rationnelle est souvent :
un audit d’opportunités pour prioriser et cadrer (valeur, faisabilité, risques)
un pilote instrumenté sur un cas d’usage à forte fréquence
puis une industrialisation seulement si le scorecard pilote est bon
C’est précisément le type de séquence que des équipes comme Impulse Lab mettent en place (audit IA, développement sur mesure, automatisation, intégration, formation), avec une logique d’exécution itérative (livraison hebdomadaire) et un suivi structuré (portail client dédié, implication du client dans le process).
Conclusion : la “meilleure agence IA” est celle qui gagne votre test, pas votre préférence
La meilleure façon de choisir une agence IA à Paris sans biais est de transformer la sélection en protocole : même brief, même test, mêmes critères, mêmes preuves demandées. Vous réduisez l’effet démo, vous évitez le “choix au feeling”, et vous maximisez vos chances d’obtenir une IA utile, intégrée, gouvernée, puis réellement adoptée.
Si vous voulez aller plus vite, vous pouvez utiliser ce cadre comme base d’échange avec Impulse Lab via leur site : impulselab.ai.