Best AI Agency in Paris: How to Compare Without Bias
Intelligence artificielle
Stratégie d'entreprise
Stratégie IA
ROI
Automatisation
Choosing the **best AI agency in Paris** often feels like a pitch contest. Impressive demos, prestigious logos, promises of "ROI in 2 weeks"... then, six months later, a POC that never goes to production because data is shaky, integration is too expensive, or...
February 26, 2026·9 min read
Choosing the best AI agency in Paris often feels like a pitch contest. Impressive demos, prestigious logos, promises of "ROI in 2 weeks"... then, six months later, a POC that never goes to production because data is shaky, integration is too expensive, or governance wasn't thought through.
The goal of this article is not to tell you which agency is "the best" in absolute terms, but to give you a comparative, reproducible, and unbiased method, adapted for SMEs and scale-ups that want to structure their AI adoption (automation, assistants, agents, RAG, integrations) with measurable results.
Why "best AI agency in Paris" is a bad question (and how to replace it)
The word "best" mixes three different subjects.
Technical competence (architecture, security, software quality, model evaluation).
Product competence (ability to frame a use case, define a KPI, deliver a useful V1, iterate).
Execution compatibility (your stack, your constraints, your pace, your data maturity level, your organization).
The right question therefore becomes: "Which AI agency in Paris is the best for our use case, with our constraints, and a clear path to production?"
To answer this without bias, you must compare based on evidence, not impressions.
The most frequent biases when comparing an AI agency (and how to neutralize them)
Selection is rarely "rational". It is influenced by very classic cognitive biases, and AI amplifies them because the demo can be spectacular.
Bias 1: The demonstration bias ("wow effect")
A fluid demo often hides what is expensive: data ingestion, access rights, logs, tests, production run, support.
Antidote: ask for a demo on your data or, at a minimum, on a representative anonymized corpus, with a test protocol.
Bias 2: The brand bias (logos, "references", media presence)
A big brand may be relevant, or totally oversized for an SME (cost, heaviness, prioritization).
Antidote: compare on an equal scope (same deliverable, same deadline, same security constraints, same level of integration).
Bias 3: The technical authority bias
Very specialized discourse (LLMOps, agents, MCP, multi-model) can inspire confidence, without proving the ability to deliver.
Antidote: demand concrete artifacts (examples of runbooks, scorecards, test plans, architecture diagrams) rather than a speech.
Bias 4: Price anchoring
The first quote serves as an anchor, and everything else is "expensive" or "cheap" without being linked to value.
Antidote: compare the TCO (Total Cost of Ownership) over 6 to 12 months: build, integrations, licenses/APIs, monitoring, RAG maintenance, training, compliance.
Bias 5: The "tool first" bias
Some agencies sell a stack before framing the need, or push a tool because they are partners.
Antidote: start with a KPI and a constraint (data, GDPR, latency, budget), then only discuss the solution afterwards.
Bias 6: The proximity bias
"They are in Paris, we can meet, so it will work." Proximity helps, but does not replace a method.
Antidote: formalize an execution framework (rituals, milestones, responsibilities, pilot exit criteria).
Bias 7: Confirmation bias
You already have a preference, and you look for elements that confirm it.
Antidote: use a scoring grid before meetings, then update it afterwards, not the other way around.
The proofs to ask for (rather than promises)
To compare without bias, ask for verifiable elements. A serious agency shouldn't "open" everything, but must be able to show anonymized examples and explain its standards.
What you must verify
Proof expected
How to avoid the illusion
Ability to frame value
Example of framing (objective, scope, KPI, baseline)
On compliance, you can also demand that the provider be capable of discussing the implications of GDPR and the European framework (notably the EU AI Act). For risk management, the NIST AI RMF framework often serves as a pragmatic basis.
A simple scoring grid (usable internally, even without an AI expert)
You don't need a complicated model. A good scorecard must be short, shared, and linked to your reality.
Criterion
Recommended weight
Example verification question
Understanding of the use case and KPI
20%
"What is the baseline and what is a realistic gain in 30 days?"
Integration (stack, data, tools)
20%
"What are the minimal integrations for a useful V1?"
Security, GDPR, governance
15%
"What data goes out, where, for how long, with what traces?"
Delivery method (cadence, iterations)
15%
"What are the weekly deliverables, and how do we decide go/no-go?"
Reliability (tests, evaluation, monitoring)
15%
"What test protocol before pilot, then continuously?"
Total cost (6-12 months) and control of variables
10%
"What recurring costs and what caps?"
Skills transfer (adoption)
5%
"What training plan at the point of usage?"
Practical advice: have at least two people score (business + tech/ops). Divergences are often more instructive than the average.
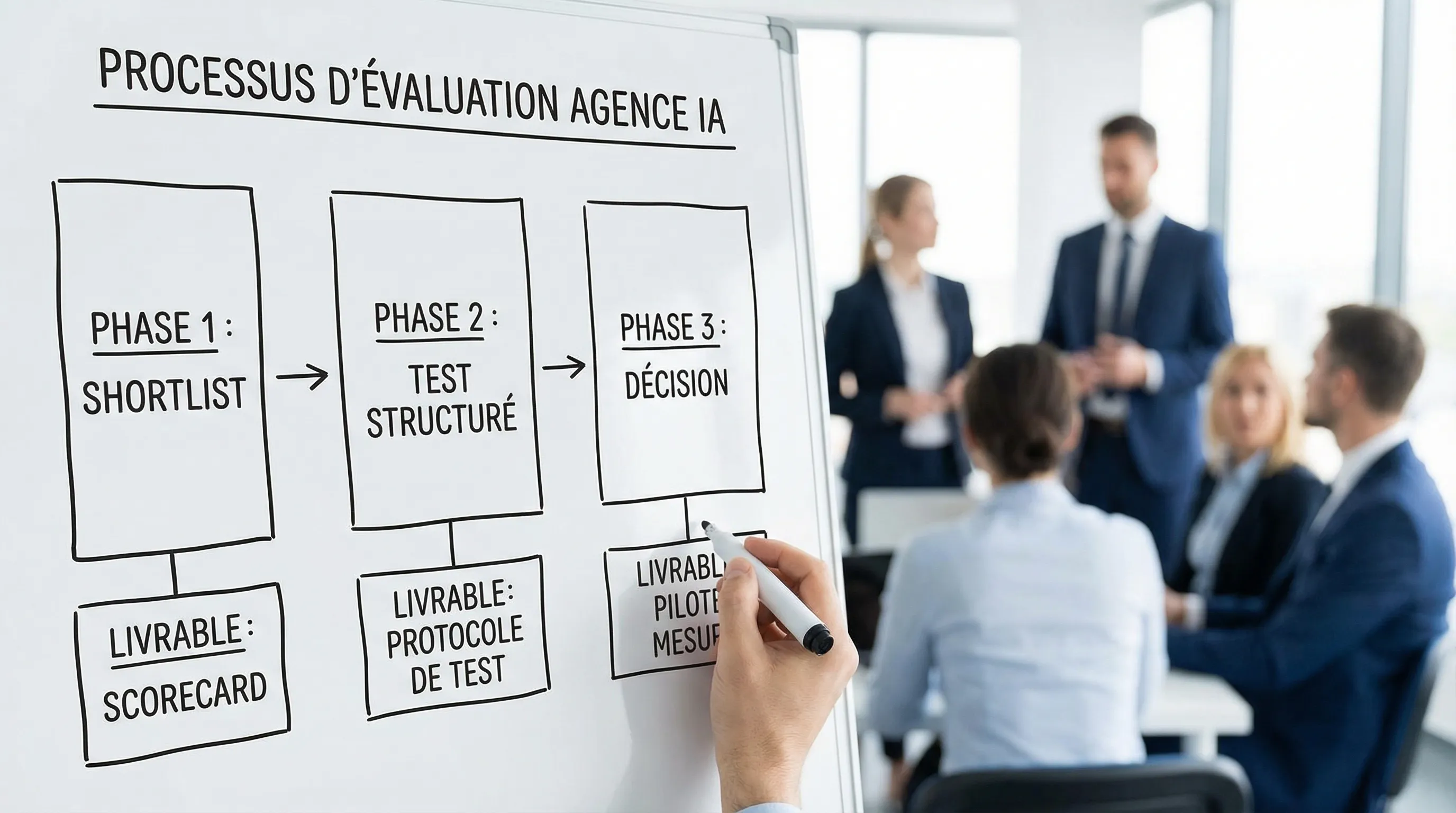
A "bias-free" protocol in 10 days to compare 3 agencies (without spending 2 months)
The classic mistake is to do 6 meetings of 45 minutes and choose "on feeling". Instead, put everyone in the same funnel.
Day 1: Internal framing (30 to 60 minutes)
Fix:
1 priority use case (not 5)
1 North Star KPI (time, resolution rate, margin, conversion)
If you don't have this framing, an opportunity audit is often the most profitable step, because it avoids starting on the wrong project (Impulse Lab details this format in its article on the strategic AI audit).
Day 2: Identical mini-brief sent to agencies
A one-page document is enough: context, use case, KPI, stack, constraints, deadline.
Days 3 to 5: "Comparison workshop" (60 minutes per agency)
Same agenda for everyone:
reformulation of the need
V1 approach proposal (minimal scope)
risks and guardrails
TCO estimation and planning
Day 6: Structured test (asynchronous)
Give the same pack to each agency: 10 to 20 real examples (anonymized), a security rule, and an instruction.
The goal is not to get a finished app, but to evaluate: quality, transparency, method, rigor.
Days 7 to 8: Reading deliverables and scoring
You score cold, then prepare 5 "blocking" questions per agency.
Day 9: Clarification call (30 minutes)
Only on unclear points. No re-pitching.
Day 10: Decision and pilot framing
You choose and contract a measured pilot, with exit criteria.
The questions that quickly reveal an AI agency's maturity
You don't need an endless list. A few questions "that sting" are enough to distinguish a production-oriented team from a demonstration-oriented team.
Measurement: "What exact KPI, how do we measure it, and how often do we review?"
Data: "What data is necessary, who owns it, and what is the plan if it is incomplete?"
Integration: "In which tool does the user see the result (CRM, helpdesk, Slack, internal app)?"
Reliability: "What is your test protocol (scenarios, golden set), before and after production deployment?"
Security: "What protections against exfiltration, prompt injection, PII leaks?"
Costs: "What variable costs, and what guardrails (cache, model routing, limits)?"
Adoption: "Who is trained, when, and how do we avoid the tool being abandoned at D+30?"
On the integration and architecture part, a good signal is the ability to speak "cleanly" about integration models (API, AI gateway, RAG, tool-calling). If you want to dig deeper, Impulse Lab's guide on AI API integration models gives useful vocabulary to challenge a provider.
Warning signals (specific to Generative AI in 2026)
Some signals should make you slow down, even if the team is nice and the demo convincing.
"We'll do everything with an autonomous agent" from V1
Agents are powerful, but they require more guardrails (actions, idempotency, rights, logs). Starting too "agentic" increases risk.
Absence of RAG strategy or truth management
If the agency cannot explain how it limits hallucinations (sources, RAG, constraints, verification), you are buying risk.
No observability plan
Without logs and metrics, you steer neither quality, nor costs, nor compliance.
Confusion between usage and impact
"Teams like the tool" is not a business KPI. A value-oriented agency will talk to you about baseline and impact.
(On this subject, you can rely on a typical measurement framework, like the one described in the Impulse Lab article on AI KPIs.)
Paris: real advantage or false criterion?
In Paris, the offer is abundant (web agencies that "do AI", consulting firms, data studios, freelancers, integrators). Location can help for:
framing workshops with mixed teams
change management (training, adoption)
governance (legal, DPO, CISO)
But in 80% of cases, this is not the variable that makes a project succeed. What counts is the ability to deliver quickly an integrated, measured, secured V1, then iterate.
What you should get before signing (to reduce risk)
Before launching a mission, ensure that the "starter pack" exists. This is often where the difference lies between an AI agency that prototypes and an AI agency that industrializes.
Element
Why it is critical
V1 scope and explicit exclusions
Avoids scope creep
KPI + baseline + measurement method
Avoids unprovable projects
Target architecture (even simple)
Avoids late refactoring
Data rules (classification, retention)
Avoids GDPR risks
Test protocol + acceptance criteria
Avoids "subjective quality"
Ownership and minimal runbook
Avoids abandonment after delivery
And if you want to compare faster: the "short audit, measured pilot" rule
When uncertainty is high (data, risks, choice between build and buy), the most rational strategy is often:
an opportunity audit to prioritize and frame (value, feasibility, risks)
an instrumented pilot on a high-frequency use case
then industrialization only if the pilot scorecard is good
This is precisely the type of sequence that teams like Impulse Lab implement (AI audit, custom development, automation, integration, training), with an iterative execution logic (weekly delivery) and structured monitoring (dedicated client portal, client involvement in the process).
Conclusion: the "best AI agency" is the one that wins your test, not your preference
The best way to choose an AI agency in Paris without bias is to transform the selection into a protocol: same brief, same test, same criteria, same proofs requested. You reduce the demo effect, you avoid "feeling-based choices", and you maximize your chances of obtaining a useful, integrated, governed, then truly adopted AI.
If you want to move faster, you can use this framework as a basis for discussion with Impulse Lab via their site: impulselab.ai.