Une API d’IA peut sembler “bon marché” sur un POC… puis devenir une ligne de dépense imprévisible dès que vous mettez le cas d’usage dans un process réel (support, ventes, ops) et que le volume monte. En 2026, le piège le plus courant n’est pas le prix affiché du modèle, mais **l’écart entre coût “t...
janvier 23, 2026·9 min de lecture
Une API d’IA peut sembler “bon marché” sur un POC… puis devenir une ligne de dépense imprévisible dès que vous mettez le cas d’usage dans un process réel (support, ventes, ops) et que le volume monte. En 2026, le piège le plus courant n’est pas le prix affiché du modèle, mais l’écart entre coût “tokens” et coût total (TCO), ajouté aux quotas (rate limits) qui forcent des compromis d’architecture.
Ce guide vous aide à lire les tarifs, à comprendre les quotas, et à anticiper les coûts cachés pour piloter un budget API AI sans surprises.
Comment une API AI est facturée (et pourquoi vos estimations dérapent)
La plupart des fournisseurs facturent principalement l’inférence (l’usage du modèle) selon une métrique proche de “volume de texte”. Les détails varient, mais les sources de facturation se retrouvent souvent dans ces familles.
Le point clé : la sortie est souvent plus coûteuse que l’entrée selon les modèles et les offres. Et surtout, l’entrée grossit vite en production (contexte, traces, policies, outils).
Pour vérifier les prix réels, fiez-vous aux pages officielles de votre provider, par exemple :
2) Modèles “raisonneurs”, outils et temps de calcul
Certains modèles facturent non seulement le texte, mais aussi des paramètres liés au raisonnement ou à l’outillage (tool use). Même quand ce n’est pas explicite, la facture augmente parce que :
vous faites plus d’appels (planification + exécution),
vous générez des réponses plus longues (justification, étapes),
vous multipliez les tours de conversation.
3) Embeddings, vectorisation et recherche (RAG)
Dès que vous utilisez un assistant “avec connaissance”, vous avez souvent :
un coût de vectorisation (embeddings) lors de l’indexation,
un coût de recherche (base vectorielle),
parfois un coût de reranking (réordonnancement des passages).
C’est rarement le poste dominant au début, mais c’est un coût structurel qui s’ajoute au fil des contenus.
Selon les fournisseurs et architectures, vous pouvez aussi payer :
du batch (moins cher, mais plus lent, utile pour la génération offline),
du cache (réduction de coût si prompts similaires),
du stockage de fichiers, des logs, ou des connecteurs,
des options de sécurité (SSO, audit, isolation, clauses contractuelles).
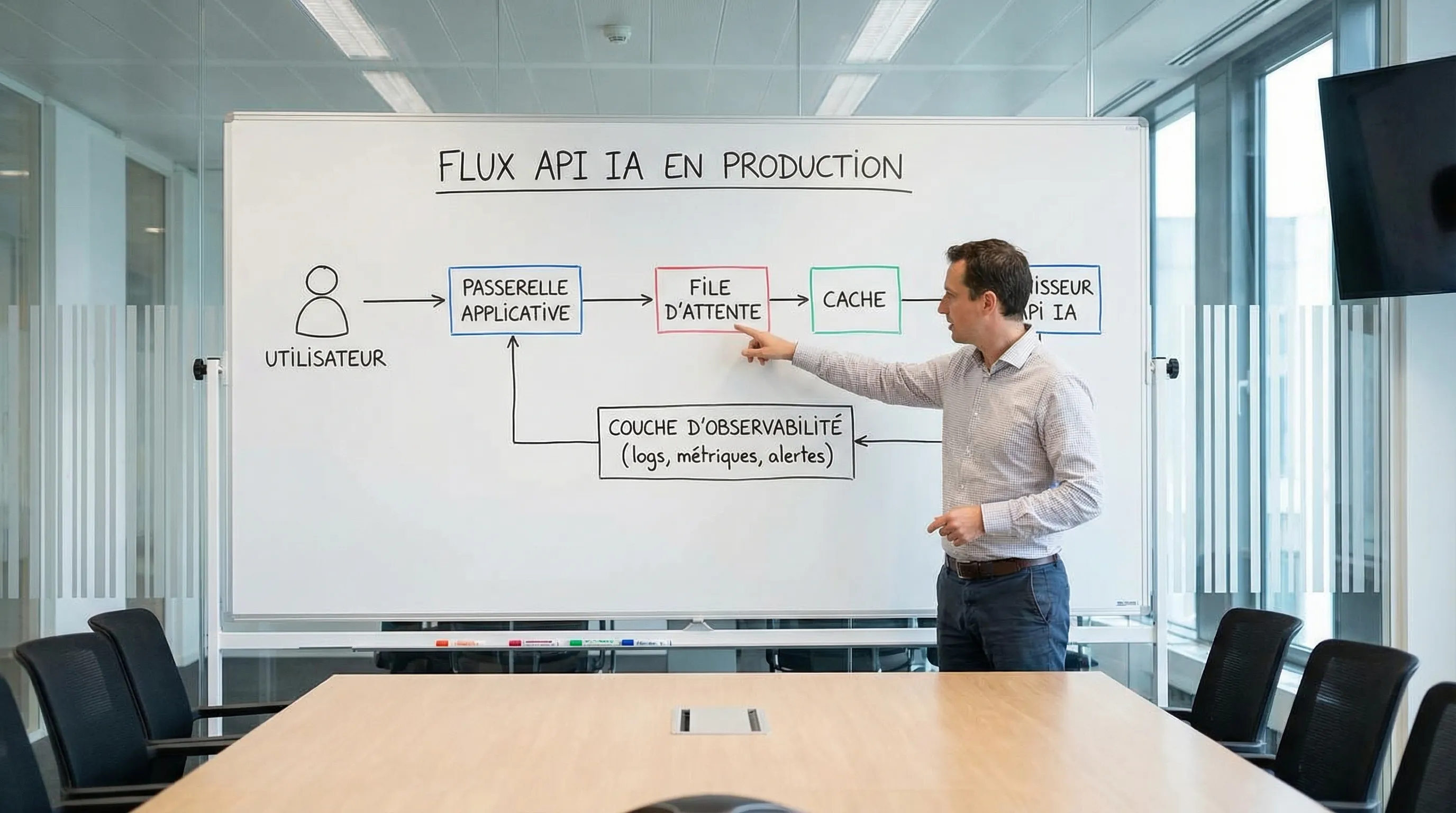
Quotas et rate limits : ce qui casse en prod si vous ne l’anticipez pas
Un quota n’est pas qu’un détail “tech”. C’est un sujet business : si votre API AI plafonne, vous dégradez l’expérience utilisateur, ou vous “brûlez” votre budget en retries et contournements.
Les limites les plus fréquentes :
Requêtes par minute (RPM) : nombre d’appels autorisés.
Tokens par minute (TPM) : volume total (entrée + sortie) par minute.
Concurrence : nombre de requêtes simultanées.
Quotas journaliers / mensuels : plafond d’usage.
Voici une grille simple pour traduire ces quotas en décisions d’architecture.
Quota courant
Symptôme côté produit
Risque business
Réponse technique typique
RPM trop bas
files d’attente, latence
baisse conversion, churn
mise en queue, batch, pooling
TPM trop bas
refus sur gros contextes
réponses plus pauvres
réduction contexte, RAG plus fin
Concurrence limitée
pics ingérables
incidents aux heures de pointe
autoscaling + throttling + cache
Plafond budget/usage
coupure brutale
arrêt de service
budget guardrails + fallback
Un point souvent oublié : les retries coûtent double
Si vous avez des timeouts, des erreurs 429 (rate limit) ou 5xx, votre système va souvent “réessayer”. Sans garde-fous, vous payez :
des appels inutiles,
une surcharge qui aggrave le quota,
une UX dégradée.
En pratique, la stratégie de retry fait partie du modèle financier.
Les coûts cachés d’une API AI (ceux qui explosent après le POC)
Le coût tokens est visible, mais il est rarement le coût dominant sur 6 à 12 mois. Voici les postes qui surprennent le plus les PME et scale-ups.
1) Contexte, prompts et “fuites de tokens”
En prod, vous ajoutez vite :
un system prompt long (règles, conformité, ton),
un historique de conversation,
des extraits de documents,
des formats de sortie stricts (JSON),
des garde-fous (policies, refus, disclaimers).
Résultat : un assistant qui “coûtait” 800 tokens en POC passe à 4 000 tokens par interaction, sans que l’utilisateur ne voie une différence majeure.
2) Observabilité, évaluation, logging
Pour piloter le ROI et limiter le risque, il faut mesurer. Cela induit :
instrumentation (traces, événements),
stockage de logs (avec masquage PII),
jeux de tests (“golden set”),
évaluations régulières.
Sans mesure, vous ne voyez pas les dérives de coût et de qualité. Avec mesure, vous ajoutez un coût, mais vous reprenez le contrôle.
Même si la techno marche, l’adoption peut échouer. Or, l’adoption a un coût :
formation des équipes,
mise à jour des playbooks,
ajustements UX,
gestion des escalades vers un humain.
Sans adoption, vous payez… sans ROI.
Méthode simple pour estimer votre budget API AI (sans “tableur infini”)
L’objectif ici est de produire une estimation utile en 30 à 60 minutes, puis de l’affiner avec des mesures réelles.
Étape 1 : décrire 3 scénarios d’usage
Prenez 3 scénarios représentatifs :
un cas “simple” (question courte),
un cas “moyen” (contexte + une source),
un cas “complexe” (RAG + outils + contrôle).
Pour chacun, estimez :
tokens entrée,
tokens sortie,
nombre d’appels (un tour ou plusieurs).
Étape 2 : modéliser le volume mensuel
Définissez :
interactions par utilisateur et par semaine,
nombre d’utilisateurs,
croissance (ex. +10% / mois).
Étape 3 : appliquer une formule de coût “provider” paramétrique
Sans figer de prix, utilisez une formule générique :
Coût mensuel modèle = (tokens entrée / 1M) × prix entrée + (tokens sortie / 1M) × prix sortie
Puis ajoutez un facteur de prudence :
+20% à +50% pour tenir compte des retries, des dérives de prompt, des cas longs.
Étape 4 : ajouter le TCO non-tokens
Le plus utile est de le rendre visible, même en fourchette.
Poste TCO
Question de cadrage
Souvent oublié quand…
Intégration SI
Quelles apps à connecter (CRM, support, ERP) ?
le POC est “standalone”
Sécurité & conformité
PII ? données sensibles ? audit requis ?
on teste sur des données fictives
RAG & contenus
Qui maintient la connaissance ?
on injecte 3 PDFs “pour voir”
Observabilité & KPI
Quelles métriques hebdo ? quelles alertes ?
on mesure seulement “ça marche”
Exploitation
Qui on-call ? quel fallback si l’API tombe ?
le trafic est faible
Réduire la facture sans dégrader la qualité : leviers pragmatiques
Voici des leviers qui marchent bien en PME et scale-ups, surtout quand le volume commence à monter.
Réduire le contexte : ne gardez pas tout l’historique, résumez, ou n’injectez que des extraits pertinents.
RAG plus “chirurgical” : moins de passages, mais mieux sélectionnés (chunking, reranking).
Cache : cache de réponses sur questions fréquentes, ou cache sur prompts stables.
Batch pour l’offline : génération de fiches, synthèses, enrichissements en différé.
Garde-fous de sortie : limiter la longueur, imposer des formats, éviter les digressions.
Router les modèles : modèle économique pour 80% des cas, modèle premium seulement quand nécessaire.
Throttling et file d’attente : mieux vaut “ralentir proprement” que partir en retries.
Observabilité coût unitaire : coût par ticket résolu, par lead qualifié, par document traité.
Quand une API AI n’est plus le bon choix (ou doit être complétée)
L’API est souvent le meilleur choix pour démarrer vite, mais certains signaux indiquent qu’il faut évoluer :
vous avez des volumes très élevés et un coût unitaire qui devient stratégique,
vous avez des contraintes fortes de souveraineté ou de données sensibles,
votre cas d’usage requiert une latence très basse et stable,
vous devez maîtriser finement la qualité via des pipelines spécifiques.
Dans ce cas, la réponse n’est pas forcément “tout self-host”. Souvent, une stratégie hybride fonctionne : API pour certains usages, optimisation RAG, cache, routage, ou modèles alternatifs selon les contraintes.
FAQ
Qu’est-ce qui coûte le plus dans une API AI : les tokens ou le reste ? Le coût tokens est le plus visible, mais sur 6 à 12 mois, l’intégration, la sécurité, la maintenance RAG et l’observabilité pèsent souvent davantage dans le TCO.
Quels quotas dois-je regarder avant de lancer un chatbot en production ? RPM, TPM, concurrence, quotas journaliers, et les comportements en cas de 429/timeouts. Traduisez-les en impacts UX (latence, files d’attente) avant de déployer.
Pourquoi mon budget explose alors que le trafic augmente “un peu” ? Parce que l’augmentation de volume s’accompagne souvent d’une augmentation de contexte (plus de sources, plus de tours, plus de règles), et de retries si les rate limits ne sont pas gérés.
Comment estimer un budget sans connaître les prix exacts des modèles ? Faites une estimation paramétrique (prix entrée/sortie par million de tokens) et calculez sur 3 scénarios. Ensuite, remplacez les paramètres par les prix officiels de votre provider.
Comment éviter les coûts cachés dès le POC ? Instrumentez dès le début : tokens par interaction, coût par cas d’usage, taux d’erreur/retry, et un KPI métier associé. Un POC sans mesure est un POC qui surprend en production.
Besoin d’un budget API AI prévisible (et d’une architecture qui tient la charge) ?
Si vous préparez un déploiement en production, l’enjeu est double : tenir vos quotas et tenir votre TCO. Impulse Lab accompagne les PME et scale-ups via des audits d’opportunité, des intégrations propres et sécurisées, et des solutions IA sur mesure.
Vous pouvez nous contacter via impulselab.ai pour cadrer un cas d’usage, estimer un budget réaliste et mettre en place des garde-fous coûts/qualité dès la V1.