Orchestration d’agents IA : stack minimale pour passer en prod
Intelligence artificielle
Stratégie IA
Outils IA
Automatisation
Passer d’un agent IA qui marche “en démo” à un agent qui tient la charge, respecte vos règles, et reste exploitable sur la durée, c’est rarement une question de modèle. C’est une question d’**orchestration d’agents IA** : comment vous exécutez des tâches multi-étapes, comment vous contrôlez les acti...
mars 06, 2026·9 min de lecture
Passer d’un agent IA qui marche “en démo” à un agent qui tient la charge, respecte vos règles, et reste exploitable sur la durée, c’est rarement une question de modèle. C’est une question d’orchestration d’agents IA : comment vous exécutez des tâches multi-étapes, comment vous contrôlez les actions, comment vous tracez, comment vous rejouez, et comment vous mesurez.
L’objectif de cet article : vous donner une stack minimale (réaliste pour PME et scale-ups) pour mettre des agents en production sans construire une usine à gaz.
Ce qu’on appelle “orchestration d’agents IA” (et pourquoi ça casse en prod)
Un agent IA, au sens opérationnel, c’est un système qui observe, raisonne, puis agit via des outils (API, CRM, helpdesk, ERP, fichiers, messagerie). L’orchestration est la couche qui transforme ce comportement “agentique” en exécution contrôlée :
gestion d’état (ce qui a déjà été fait, ce qui reste à faire)
planification et enchaînement des étapes
timeouts, retries, files d’attente, concurrence
permissions et politiques d’action
traçabilité, observabilité et rejouabilité
En production, les problèmes récurrents ne sont pas “le prompt” mais :
l’agent exécute deux fois une action (double création de ticket, double email)
un outil tombe, le workflow reste bloqué
le contexte est incomplet, l’agent “devine”
personne ne peut expliquer pourquoi une décision a été prise
les coûts explosent parce que le système boucle ou raisonne trop longtemps
Pour poser les bases, vous pouvez relire la définition d’un agent IA et, si vous visez de l’autonomie, les points clés sur les garde-fous et la validation.
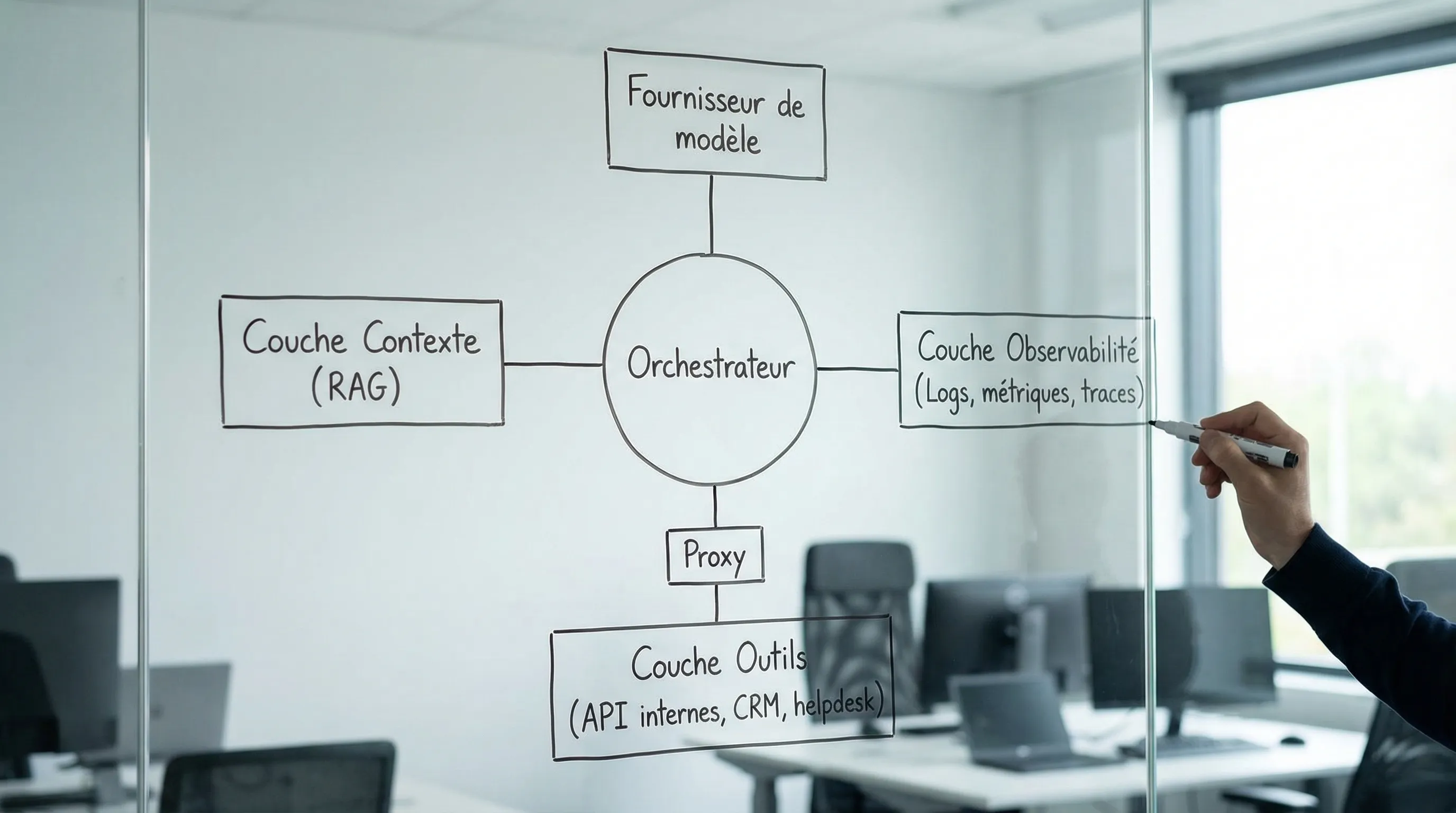
La stack minimale en 6 briques (celle qui suffit pour 80% des cas)
Voici une stack volontairement “minimaliste”, conçue pour être industrializable sans dépendre d’une équipe MLOps complète.
1) Un point d’entrée stable (API, webhook, cron)
Vous avez besoin d’un déclencheur clair et testable :
API (ex. “triage support”, “générer un devis”, “qualifier un lead”)
Webhook (nouveau ticket, nouveau message, nouveau deal)
Cron (relances quotidiennes, mise à jour, contrôles)
C’est trivial, mais c’est ce qui permet de versionner le comportement, de l’intégrer au SI, et de faire des tests E2E.
2) Un orchestrateur (gestion d’état, étapes, reprises)
C’est la pièce centrale. Sans elle, vous avez un script fragile.
Fonctions minimales à exiger :
state explicite (objet JSON stocké, ou état en base)
retries et timeouts par étape
idempotence (rejouer sans doubler les actions)
gestion d’erreurs (fallback, escalade humaine)
Implémentation : ça peut être une librairie d’orchestration “agent workflow” ou un orchestrateur plus généraliste (workflow engine), selon votre niveau de criticité. L’important est moins le nom de l’outil que la présence de ces capacités.
3) Une couche “outils” séparée (actions et permissions)
Un agent ne devrait pas appeler vos systèmes métiers en direct sans contrôle. La pratique robuste est de passer par une couche outils qui :
expose des fonctions stables (contrats d’API)
applique les droits (qui a le droit de faire quoi)
logue l’appel et le résultat
filtre ou masque les données sensibles
Si vous cherchez une standardisation propre des intégrations, le Model Context Protocol (MCP) devient un vrai accélérateur (interop, gouvernance, réutilisation des connecteurs), surtout quand vous multipliez les outils.
4) Une couche contexte fiable (RAG + source de vérité)
Dès que l’agent doit “savoir” quelque chose sur votre entreprise, vos offres, vos process, vos clients, vous devez le connecter à une source.
Stack minimale côté contexte :
une source de vérité (docs, base produit, helpdesk, CRM)
un mécanisme de récupération (RAG) avec citations, filtres, et fraîcheur
un cache simple (pour éviter de recalculer du contexte identique)
métriques (latence, taux d’échec, escalades, coût par exécution)
un “jeu de tests” (golden set) pour réévaluer à chaque changement
Vous pouvez vous inspirer d’une approche simple et reproductible comme celle décrite dans Enterprise AI Testing (même si l’article est en anglais, la méthode est applicable telle quelle).
Stack minimale, version “prête à acheter” (checklist d’architecture)
La question la plus utile est souvent : “qu’est-ce qui doit exister dès V1 pour ne pas tout réécrire au moment du passage à l’échelle ?”
Voici une checklist d’architecture minimaliste, en langage produit.
Brique
Minimum acceptable en V1
Pourquoi c’est non négociable
Signal que vous devez renforcer
Orchestration
état + retries + timeouts + idempotence
évite les doublons et les workflows bloqués
actions critiques, volume croissant
Actions/outils
proxy outils + permissions + logs
contrôle des actions, auditabilité
risques RGPD, actions financières
Contexte
RAG simple + sources identifiées + citations
réduit les “inventions”
multiple sources, données mouvantes
Guardrails
schéma de sortie + HITL sur actions sensibles
baisse le risque opérationnel
incidents, escalades fréquentes
Observabilité
logs structurés + coût par run + erreurs
debug, pilotage ROI
SLA, objectifs de qualité
Évaluation
golden set + re-run avant release
évite la régression silencieuse
changements fréquents de prompt/modèle
Les 3 décisions qui simplifient vraiment la mise en prod
Décision 1 : traiter l’agent comme un mini-produit (et pas un script)
Un agent “utile” a :
un périmètre explicite (ce qu’il fait, ce qu’il ne fait pas)
un KPI (temps gagné, taux de résolution, qualité, revenu)
une routine de release (modifs petites, fréquentes, testées)
C’est exactement ce qui évite le cimetière de POC.
Décision 2 : séparer “raisonnement” et “action”
Un pattern robuste :
le modèle propose un plan et une action candidate
le système valide (droits, contraintes, schémas)
l’action est exécutée par une fonction outillée
Ce découplage limite les dégâts, et rend l’ensemble testable.
Quelle différence entre un agent IA et un workflow d’automatisation classique ? Un workflow classique exécute des règles déterministes. Un agent combine décision probabiliste (LLM) et exécution d’actions, d’où le besoin d’orchestration, de garde-fous et d’évaluation.
Faut-il absolument un framework d’orchestration dédié “agents” ? Non. Il vous faut surtout état, reprises, timeouts, idempotence et traçabilité. Certains frameworks agents facilitent la modélisation, mais un workflow engine généraliste peut suffire si bien cadré.
Le MCP est-il obligatoire pour l’orchestration d’agents IA ? Non, mais c’est un accélérateur quand vous connectez plusieurs outils. MCP standardise l’accès aux ressources et aux outils, ce qui réduit les intégrations sur mesure et facilite la gouvernance.
Comment éviter que l’agent hallucine en production ? En priorité, connectez-le à une source de vérité (RAG), imposez des sorties structurées, affichez des citations, et bloquez les actions si l’information n’est pas trouvée ou si la confiance est trop faible.
Quels sont les KPIs minimaux à suivre ? En général : taux de succès (issue correcte), taux d’escalade humaine, latence, coût par exécution, et un KPI métier (temps gagné, taux de résolution, conversion, etc.).
Quand passer d’un agent “assisté” à un agent plus autonome ? Quand vous avez des logs fiables, des tests reproductibles, des actions idempotentes, et une preuve que l’autonomie améliore un KPI sans augmenter le risque de façon disproportionnée.
Besoin d’une stack minimale adaptée à votre SI (et livrable rapidement) ?
Si vous avez déjà un cas d’usage clair, Impulse Lab peut vous aider à définir une architecture minimale (orchestration, RAG, outils, garde-fous, observabilité) et à livrer une V1 pilotable en cycles courts.
Pour partir du bon périmètre, commencez par un audit d’opportunités IA.
Si vous avez déjà un POC, on peut le transformer en pilote instrumenté (KPI, logs, contrôles, runbook).
Contactez l’équipe via impulselab.ai pour cadrer votre cas d’usage et éviter la réécriture au moment du passage en production.