AI API: Guide to Pricing, Quotas, and Hidden Costs
Intelligence Artificielle
Stratégie IA
Outils IA
An AI API may seem cheap during a POC but can become unpredictable in production. In 2026, the trap isn't the model price, but the gap between "token" costs and Total Cost of Ownership (TCO), plus quotas forcing architectural trade-offs.
January 23, 2026·8 min read
An AI API might seem "cheap" during a POC... then become an unpredictable expense line as soon as you put the use case into a real-world process (support, sales, ops) and volume rises. In 2026, the most common trap isn't the displayed model price, but the gap between "token" costs and Total Cost of Ownership (TCO), added to quotas (rate limits) that force architectural trade-offs.
This guide helps you read the pricing, understand the quotas, and anticipate hidden costs to manage an AI API budget without surprises.
How an AI API is Billed (and Why Your Estimates Slip)
Most providers bill primarily for inference (model usage) based on a metric close to "volume of text". Details vary, but billing sources often fall into these families.
The key point: output is often more expensive than input depending on the models and plans. And above all, input grows quickly in production (context, traces, policies, tools).
To check real prices, rely on your provider's official pages, for example:
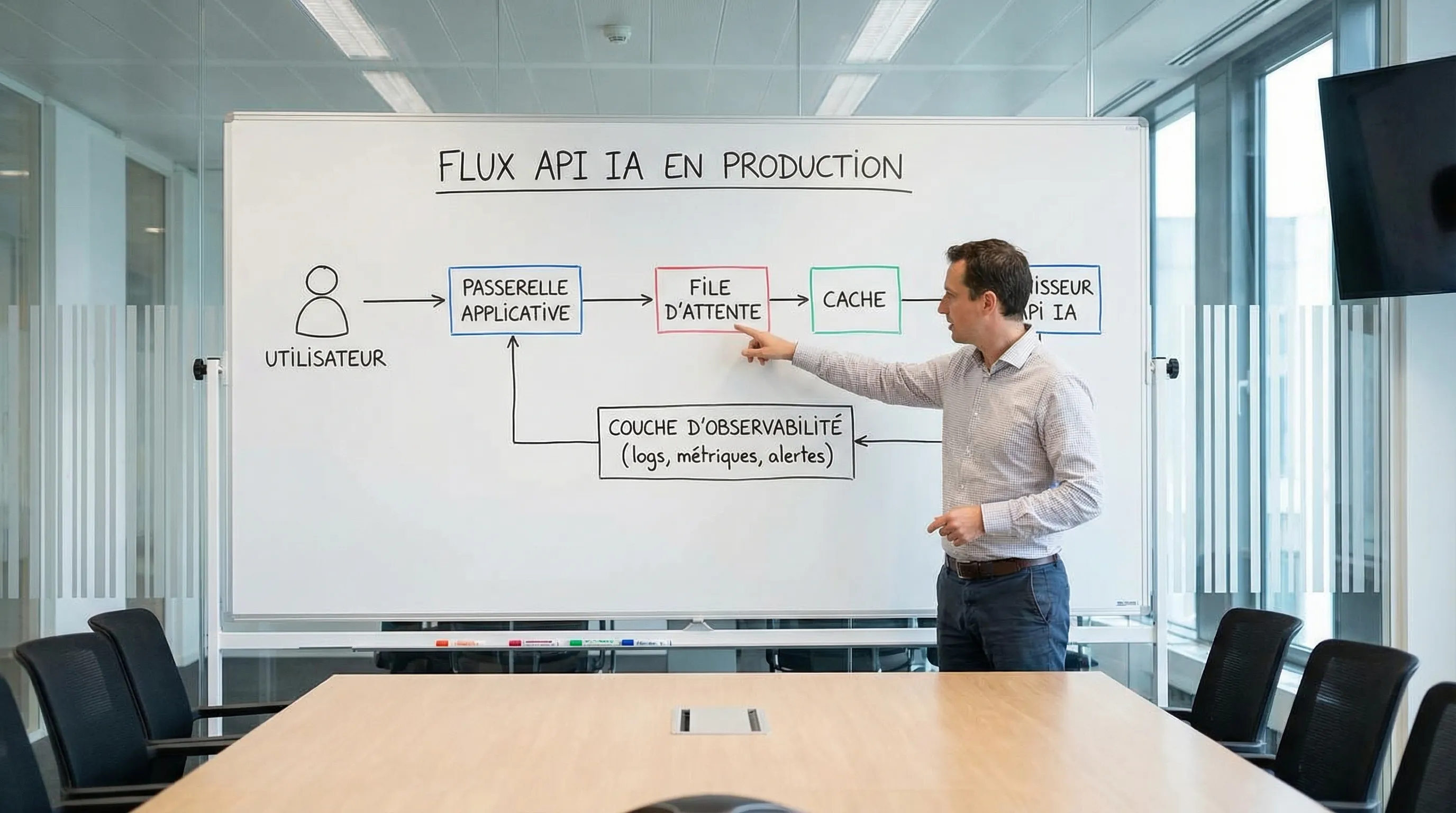
Quotas and Rate Limits: What Breaks in Prod If You Don't Anticipate It
A quota isn't just a "tech" detail. It's a business issue: if your AI API hits a ceiling, you degrade the user experience, or you "burn" your budget on retries and workarounds.
The most frequent limits:
Requests Per Minute (RPM): number of authorized calls.
Tokens Per Minute (TPM): total volume (input + output) per minute.
Concurrency: number of simultaneous requests.
Daily / Monthly Quotas: usage cap.
Here is a simple grid to translate these quotas into architectural decisions.
Common Quota
Product-side Symptom
Business Risk
Typical Technical Response
RPM too low
queues, latency
conversion drop, churn
queuing, batch, pooling
TPM too low
rejection on large contexts
poorer responses
context reduction, finer RAG
Limited Concurrency
unmanageable spikes
incidents at peak hours
autoscaling + throttling + cache
Budget/Usage Cap
brutal cutoff
service stoppage
budget guardrails + fallback
A Point Often Forgotten: Retries Cost Double
If you have timeouts, 429 errors (rate limit), or 5xx errors, your system will often "retry". Without guardrails, you pay for:
useless calls,
overload that worsens the quota,
degraded UX.
In practice, the retry strategy is part of the financial model.
The Hidden Costs of an AI API (The Ones That Explode After the POC)
The token cost is visible, but it is rarely the dominant cost over 6 to 12 months. Here are the items that surprise SMEs and scale-ups the most.
1) Context, Prompts, and "Token Leaks"
In prod, you quickly add:
a long system prompt (rules, compliance, tone),
conversation history,
document excerpts,
strict output formats (JSON),
guardrails (policies, refusals, disclaimers).
Result: an assistant that "cost" 800 tokens in POC goes to 4,000 tokens per interaction, without the user seeing a major difference.
2) Observability, Evaluation, Logging
To manage ROI and limit risk, you must measure. This induces:
instrumentation (traces, events),
log storage (with PII masking),
test sets ("golden set"),
regular evaluations.
Without measurement, you don't see cost and quality drifts. With measurement, you add a cost, but you regain control.
Route Models: economic model for 80% of cases, premium model only when necessary.
Throttling and Queuing: better to "slow down cleanly" than go into retries.
Unit Cost Observability: cost per resolved ticket, per qualified lead, per processed document.
When an AI API Is No Longer the Right Choice (Or Needs Supplementing)
The API is often the best choice to start quickly, but certain signals indicate a need to evolve:
you have very high volumes and unit cost becomes strategic,
you have strong sovereignty or sensitive data constraints,
your use case requires very low and stable latency,
you need to finely control quality via specific pipelines.
In this case, the answer isn't necessarily "everything self-hosted". Often, a hybrid strategy works: API for certain uses, RAG optimization, cache, routing, or alternative models depending on constraints.
FAQ
What costs the most in an AI API: tokens or the rest? The token cost is the most visible, but over 6 to 12 months, integration, security, RAG maintenance, and observability often weigh more in the TCO.
Which quotas should I look at before launching a chatbot in production? RPM, TPM, concurrency, daily quotas, and behaviors in case of 429/timeouts. Translate them into UX impacts (latency, queues) before deploying.
Why does my budget explode while traffic increases "a little"? Because volume increase is often accompanied by an increase in context (more sources, more turns, more rules), and retries if rate limits aren't managed.
How to estimate a budget without knowing the exact model prices? Make a parametric estimate (input/output price per million tokens) and calculate on 3 scenarios. Then, replace the parameters with your provider's official prices.
How to avoid hidden costs right from the POC? Instrument from the start: tokens per interaction, cost per use case, error/retry rate, and an associated business KPI. A POC without measurement is a POC that surprises in production.
Need a Predictable AI API Budget (and an Architecture That Handles the Load)?
If you are preparing a production deployment, the challenge is twofold: keeping your quotas and keeping your TCO. Impulse Lab accompanies SMEs and scale-ups via opportunity audits, clean and secure integrations, and custom AI solutions.
You can contact us via impulselab.ai to frame a use case, estimate a realistic budget, and put in place cost/quality guardrails from V1.