AI System: Minimal architecture for reliable deployment
Intelligence artificielle
Stratégie IA
Gouvernance IA
Gestion des risques IA
Architecture IA
Moving an AI demo to production is rarely a "model" problem. It's an **AI system** problem: how AI integrates into your tools, data, security, business rules, and daily operations.
April 23, 2026·9 min read
Moving an AI demo to production is rarely a "model" problem. It's an AI system problem: how AI integrates into your tools, your data, your security, your business rules, and your daily operations.
For an SMB or scale-up, the goal isn't to build a "heavy" platform like a large corporation. The goal is to assemble a minimal architecture that makes deployment reliable, measurable, and maintainable, right from V1.
What we (really) call an "AI system"
An AI system is the set of building blocks that allow a model (LLM, classifier, vision model, etc.) to produce operational value in a real workflow, with acceptable guarantees.
Practically, the model is just one block. An AI system also includes:
If you only build "the prompt" or "the chatbot", you are building an artifact. If you build the blocks above, you are building a system.
Why aim for a minimal (and not "complete") architecture
A minimalist architecture is one that covers the dominant risks and production requirements, without multiplying components.
It serves to avoid three classic failures:
The AI doesn't integrate: it lives in a tab, not in the tools (CRM, support, back-office), so adoption drops.
Quality is unpredictable: no evaluation protocol, no verified sources, no versioning, so trust erodes.
Operations explode: uncontrolled costs, untraceable incidents, no owner, no rollback procedure.
In 2026, it is also the most pragmatic way to prepare your deployments for governance requirements (GDPR and EU AI Act).
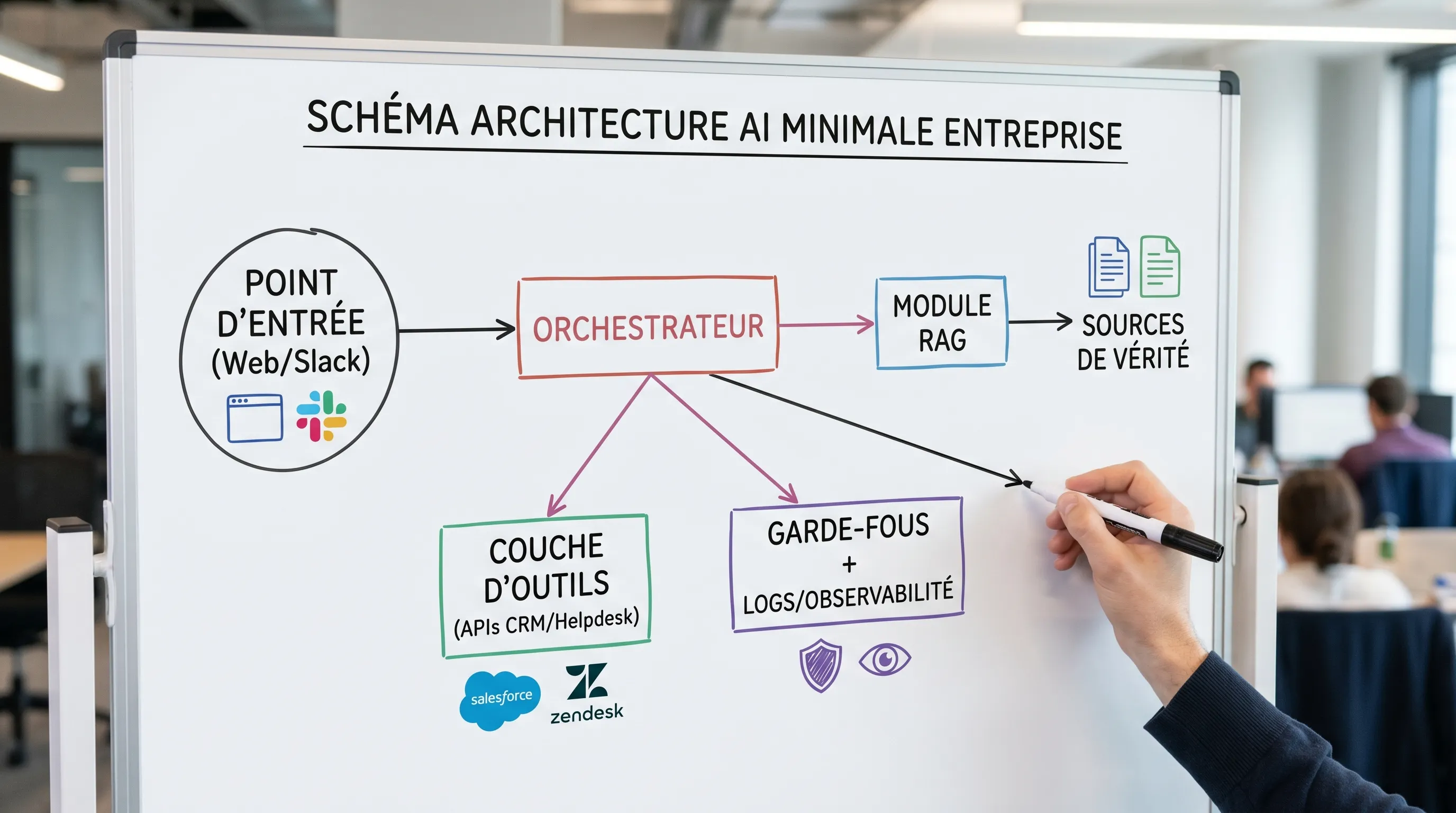
The 7 blocks of a "production-grade" minimal architecture
The goal is not to impose a stack. The goal is to not forget anything essential.
1) A clear (and instrumented) entry point
Choose only one main channel to start: website widget, Slack, Teams, internal browser extension, or a dedicated page. The rule: the entry point must allow you to track usage.
From V1, log at a minimum:
the user (or a pseudonymized identifier)
the use case (intent, type of request)
the result (response provided, action taken, escalation)
the response time
Without this, you will have usage, but no management.
2) Identity, authentication, and access control
A useful AI quickly touches sensitive data. Your minimal architecture must integrate:
authentication (SSO if possible, otherwise managed accounts)
authorization (who has the right to see what, and do what)
"boundaries" between environments (test, pilot, production)
To properly frame this block, link it to your IAM approach and the principles described in your authentication and access management system.
3) An orchestration layer (the underestimated block)
The orchestrator is the part that transforms "a model" into a "product feature". It manages in particular:
context preparation (data, history, rules)
pattern selection (simple API, RAG, tooled agent)
routing (which logic depending on the intent)
output structuring (JSON, fields, citations)
This is also where you implement "reliable" rather than "magical" behaviors: rephrasing, asking for clarification, refusal, escalation.
4) Reliable context: minimal, but serious RAG
Most assistants fail because they improvise on topics where the company already has an official answer.
A well-designed RAG (Retrieval-Augmented Generation) connects AI to your sources of truth, instead of relying on frozen knowledge. If you want a definition and principles, see the RAG entry.
In a minimal architecture, "serious" RAG includes:
selected documents (not "the whole Drive")
indexing with metadata (source, date, owner, confidentiality level)
output with citations (or at least references)
If you need to standardize the connection between models and sources/tools, the Model Context Protocol (MCP) can become a structuring block, but it is not mandatory for a V1.
5) Guardrails: quality, security, and action-first
Guardrails are not a "nice to have", they are the brakes of a vehicle.
In a minimal AI system, you need guardrails at three levels:
Inputs: filter or mask sensitive data, detect prompt injection (useful to know recommendations like OWASP Top 10 for LLM Applications).
Outputs: constrained format, citations, refusal rules, confidence thresholds.
As soon as your AI can "act" (write in a CRM, create a ticket, send an email), draw inspiration from an "action-first guardrails" logic, detailed in our content on agents and their protections (for example autonomous agents: guardrails and validation).
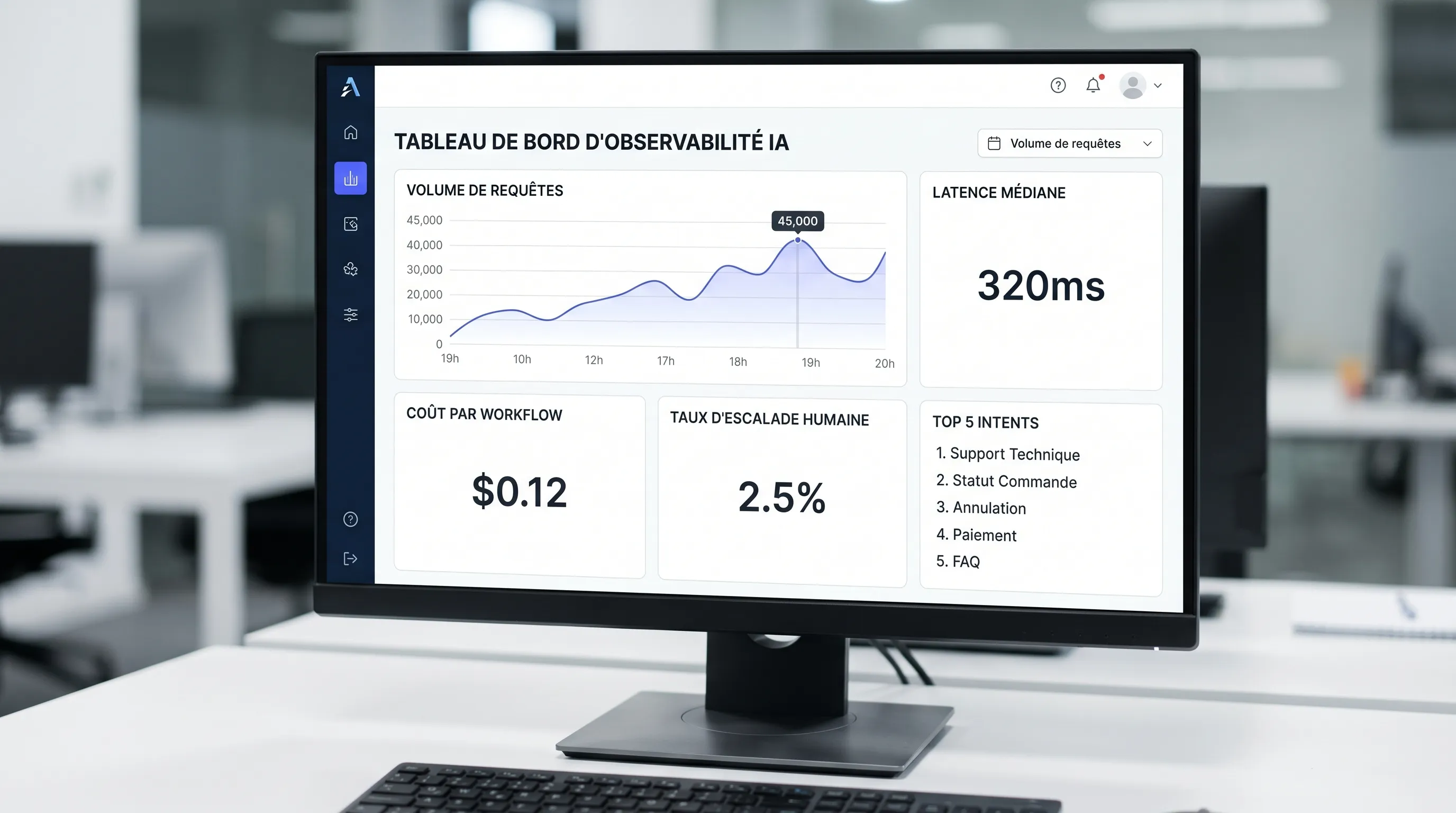
metrics: latency, escalation rate, failure rate, satisfaction or quality signal
costs: cost per request, cost per workflow, top users, top intents
The goal is not to have a "super dashboard", but to be able to answer in 5 minutes:
"Why did the assistant fail?"
"How much does it cost per week, and why?"
"Which version introduced a regression?"
7) Operations: runbook, versioning, and degraded modes
A reliable AI is an operable AI. In your minimal architecture, plan for:
a runbook (who does what, how to diagnose, how to rollback)
versioning (prompts, configs, indexes, rules)
degraded modes (e.g., "I don't know" response, human escalation, fallback to a deterministic flow)
A good test: if the "owner" is absent for a week, does the system continue to function without panic.
Choosing the minimal "shape" according to the need (copilot, RAG, agent)
Many teams over-architect because they start directly with agents. However, the right pattern depends on the risk level and the nature of the workflow.
Need
Recommended pattern
Essential blocks
Dominant risk
Help write, summarize, rephrase
API (LLM)
Orchestration, output guardrails, logs, costs
Variable quality, sensitive data
Answer "truthfully" from an internal corpus
API + RAG
RAG with citations, doc access control, evaluation
Deploy to a restricted group, with a simple ritual:
weekly review of incidents and doubtful answers
adjustment of context (sources), guardrails, and UX
KPI and cost tracking
What "reliable" means for executives (a quick test)
If you are a CEO, CTO, or Head of Ops, you can qualify reliability with 6 questions:
Integration: is it used in the tool where the work is done, or on the side?
Truth: on critical topics, do we have sources and citations?
Control: who can see what, and who can do what?
Measurement: do we have a business KPI, and a baseline?
Costs: do we know the cost per week, and the cost per useful action?
Operations (Run): can we diagnose, fix, and rollback in less than a day?
If two answers are "no", you probably have a prototype, not an AI system.
FAQ
What is an enterprise AI system? An AI system is the combination of model + orchestration + data + security + guardrails + observability + operations, which allows delivering reliable value in a workflow.
What is the minimal architecture to deploy a reliable AI? An instrumented entry point, an orchestration layer, controlled access (IAM), a reliable context (often RAG), guardrails, observability, and a runbook.
Is a RAG always necessary in an AI system? No. If the use case is writing or rephrasing without a "truth" stake, a RAG can be useless. As soon as the assistant must answer accurately based on internal content, RAG often becomes essential.
When to switch from an assistant to an agent that executes actions? When the workflow is frequent, well-bounded, and you can secure the actions (permissions, confirmations, idempotency, logs). Otherwise, start with API or RAG.
How to avoid cost drift in production? Measure the cost per workflow, add quotas/alerts, reduce the context, use caching when relevant, and remove "non-ROI" usages.
Build your minimal AI system with Impulse Lab
If you want a reliable deployment without over-architecture, Impulse Lab can help you frame the right pattern (API, RAG, guarded agent), design the minimal architecture, integrate AI into your existing tools, and instrument KPIs, security, and operations.
Depending on your maturity, you can start with an AI opportunity audit (prioritization and scoping), a V1 delivered in short cycles, or adoption training to make usages reproducible. To discuss this, you can visit the Impulse Lab website and request an initial chat.
AI and Work: Achieving Gains Without Disrupting Your Teams
For SMEs and scale-ups, the promise of AI at work is clear: save time, reduce repetitive tasks, and speed up decisions. But the risk is just as real: multiplying tools, creating shadow IT, and blurring responsibilities. Learn how to integrate AI smoothly.