AI Agent Orchestration: Minimal Stack to Go to Production
Intelligence artificielle
Stratégie IA
Outils IA
Automatisation
Moving from a "demo" AI agent to a production-ready one isn't about the model. It's about **AI agent orchestration**. Learn how to execute multi-step tasks, control actions, and ensure maintainability with a minimal stack designed for scale-ups and SMEs.
March 06, 2026·9 min read
Moving from an AI agent that works "in demo" to one that handles the load, respects your rules, and remains maintainable over time is rarely a question of the model. It is a question of AI agent orchestration: how you execute multi-step tasks, how you control actions, how you trace, how you replay, and how you measure.
The goal of this article: to give you a minimal stack (realistic for SMEs and scale-ups) to put agents into production without building an overly complex system.
What we call "AI Agent Orchestration" (and why it breaks in prod)
An AI agent, in the operational sense, is a system that observes, reasons, then acts via tools (API, CRM, helpdesk, ERP, files, messaging). Orchestration is the layer that transforms this "agentic" behavior into controlled execution:
state management (what has already been done, what remains to be done)
planning and sequencing of steps
timeouts, retries, queues, concurrency
permissions and action policies
traceability, observability, and replayability
In production, recurring problems aren't "the prompt" but:
the agent executes an action twice (double ticket creation, double email)
a tool fails, the workflow remains stuck
the context is incomplete, the agent "guesses"
no one can explain why a decision was made
costs explode because the system loops or reasons for too long
To lay the foundations, you can reread the definition of an AI agent and, if you are aiming for autonomy, the key points on guardrails and validation.
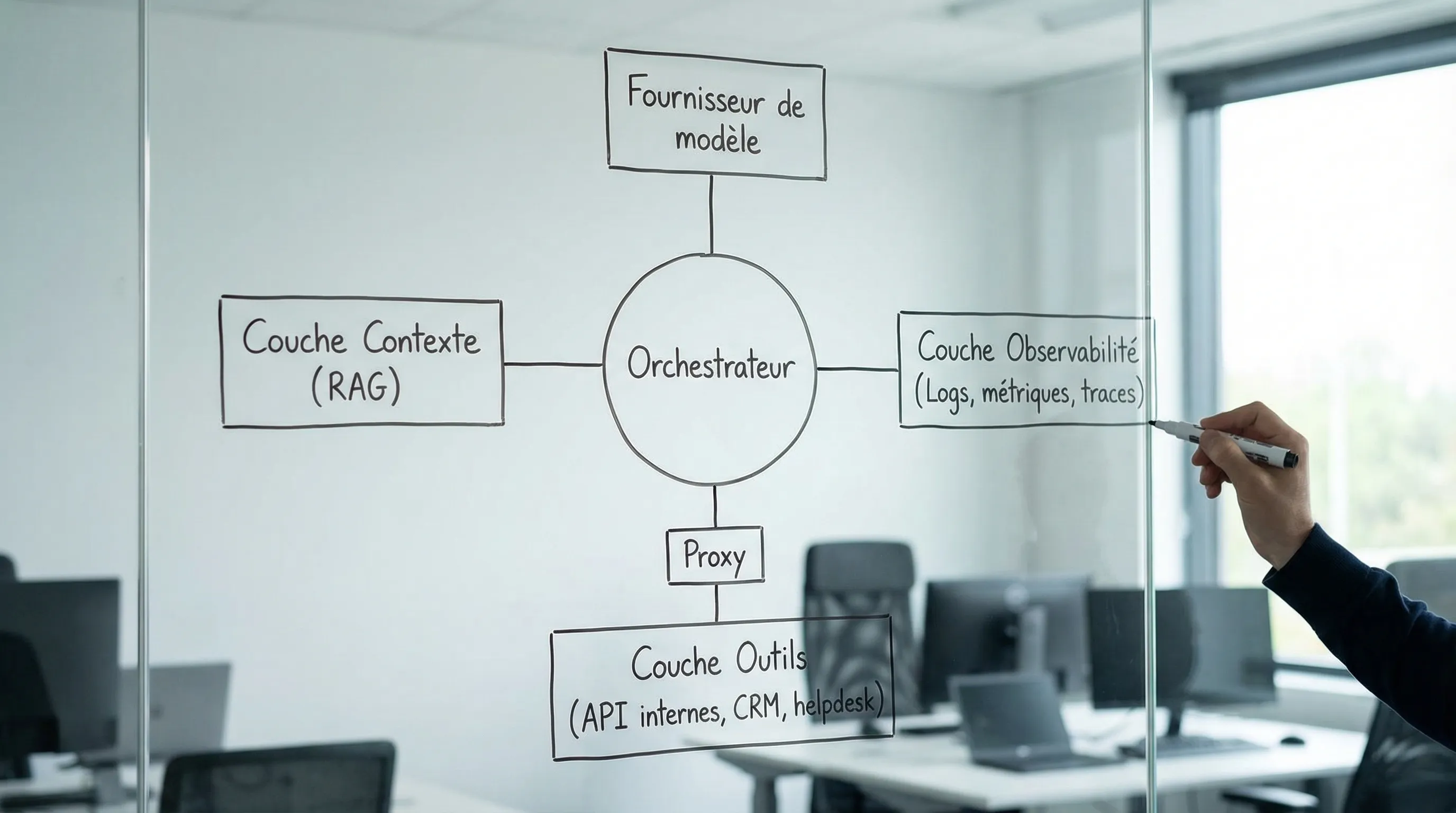
The minimal stack in 6 blocks (the one that suffices for 80% of cases)
Here is a deliberately "minimalist" stack, designed to be industrializable without depending on a full MLOps team.
1) A stable entry point (API, webhook, cron)
You need a clear and testable trigger:
API (e.g., "support triage", "generate quote", "qualify lead")
Webhook (new ticket, new message, new deal)
Cron (daily follow-ups, updates, checks)
It's trivial, but it's what allows you to version the behavior, integrate it into the IS, and perform E2E tests.
2) An orchestrator (state management, steps, retries)
This is the central piece. Without it, you have a fragile script.
Minimal functions to require:
explicit state (stored JSON object, or state in DB)
retries and timeouts per step
idempotency (replay without doubling actions)
error management (fallback, human escalation)
Implementation: this can be an "agent workflow" orchestration library or a more generalist orchestrator (workflow engine), depending on your criticality level. The name of the tool matters less than the presence of these capabilities.
3) A separate "tools" layer (actions and permissions)
An agent should not call your business systems directly without control. The robust practice is to go through a tools layer that:
exposes stable functions (API contracts)
applies rights (who has the right to do what)
logs the call and the result
filters or masks sensitive data
If you are looking for clean standardization of integrations, the Model Context Protocol (MCP) is becoming a real accelerator (interop, governance, reuse of connectors), especially when you multiply tools.
4) A reliable context layer (RAG + source of truth)
As soon as the agent needs to "know" something about your company, your offers, your processes, your clients, you must connect it to a source.
Minimal stack on the context side:
a source of truth (docs, product base, helpdesk, CRM)
a retrieval mechanism (RAG) with citations, filters, and freshness
a simple cache (to avoid recalculating identical context)
action: creation of tagged ticket, assignment, draft response
guardrails: if low confidence or VIP client, human escalation
observability: logs, cost, resolution rate without escalation
If your RAG context is clean and your actions are controlled, you get a useful agent without "dangerous" autonomy.
Production rollout in 2 to 4 weeks: realistic plan
Without making universal promises, here is a trajectory that works well when the team is available on the business side.
Week 1: Scoping and "agent contract"
Useful deliverables:
scope, failure cases, authorized actions
data and sources of truth
KPI, baseline, and security thresholds
Week 2: Orchestrated V1 + tools proxy
orchestration with state and errors
priority tool connectors
output schemas and logs
Week 3: RAG + first tests + pilot
minimal RAG (sources, simple chunking, citations)
golden set of representative scenarios
pilot on a segment (e.g., 10% of tickets)
Week 4: Hardening and runbook
cost limits, timeouts, calibrated retries
alerting (errors, latency, escalations)
runbook: how to diagnose, replay, rollback
FAQ
What is the difference between an AI agent and a classic automation workflow? A classic workflow executes deterministic rules. An agent combines probabilistic decision-making (LLM) and action execution, hence the need for orchestration, guardrails, and evaluation.
Is a dedicated "agent" orchestration framework absolutely necessary? No. You mainly need state, retries, timeouts, idempotency, and traceability. Some agent frameworks facilitate modeling, but a generalist workflow engine can suffice if well-scoped.
Is MCP mandatory for AI agent orchestration? No, but it is an accelerator when you connect multiple tools. MCP standardizes access to resources and tools, which reduces custom integrations and facilitates governance.
How to avoid the agent hallucinating in production? As a priority, connect it to a source of truth (RAG), impose structured outputs, display citations, and block actions if the information is not found or if confidence is too low.
What are the minimal KPIs to track? Generally: success rate (correct outcome), human escalation rate, latency, cost per execution, and a business KPI (time saved, resolution rate, conversion, etc.).
When to move from an "assisted" agent to a more autonomous agent? When you have reliable logs, reproducible tests, idempotent actions, and proof that autonomy improves a KPI without disproportionately increasing risk.
Need a minimal stack adapted to your IS (and deliverable quickly)?
If you already have a clear use case, Impulse Lab can help you define a minimal architecture (orchestration, RAG, tools, guardrails, observability) and deliver a pilotable V1 in short cycles.
To start with the right scope, begin with an AI opportunity audit.
If you already have a POC, we can transform it into an instrumented pilot (KPI, logs, controls, runbook).
Contact the team via impulselab.ai to frame your use case and avoid rewriting when moving to production.
Robotic Process Automation (RPA) offers a highly appealing promise: delegating time-consuming, repetitive tasks to software robots. For growing SMEs and scale-ups, the idea is simple: reduce administrative burden, improve reliability, and handle more volume without immediate hiring.