Deploying AI in the enterprise is no longer just about "innovation"; it is a **production** issue. In production, risks become concrete: data leaks, erroneous decisions, cost overruns, non-compliance, LLM-specific attacks, or simply stagnant adoption.
March 14, 2026·9 min read
Deploying AI in the enterprise is no longer just about "innovation"; it is a production issue. And in production, risks become concrete: data leaks, erroneous decisions, cost overruns, non-compliance, LLM-specific attacks, or simply stagnant adoption.
The good news is that most of these risks can be mastered with simple, auditable, and proportionate controls. The goal is not to "secure AI" theoretically, but to reduce real risk while keeping a fast time-to-value.
Why AI risks are different (and why classic IT checklists aren't enough)
A classic software executes deterministic rules. An AI solution (especially generative) produces a probabilistic result, sometimes plausible but false, and can be influenced by its input context (documents, prompts, history, connectors).
Three operational consequences follow:
Quality is a variable: you must test and monitor, not just "validate at acceptance".
Risk shifts to inputs and context (data, documents, permissions, connectors, prompts), as much as to the code.
The attack surface changes: prompt injection, data exfiltration via tools, jailbreaks, agent hijacking, etc.
To structure a robust approach, it is useful to rely on recognized frameworks like the NIST AI Risk Management Framework (AI RMF) and LLM-oriented security repositories like the OWASP Top 10 for LLM Applications. In Europe, compliance also plays out with GDPR and the AI Act (progressive implementation), which imposes a logic of proof and governance.
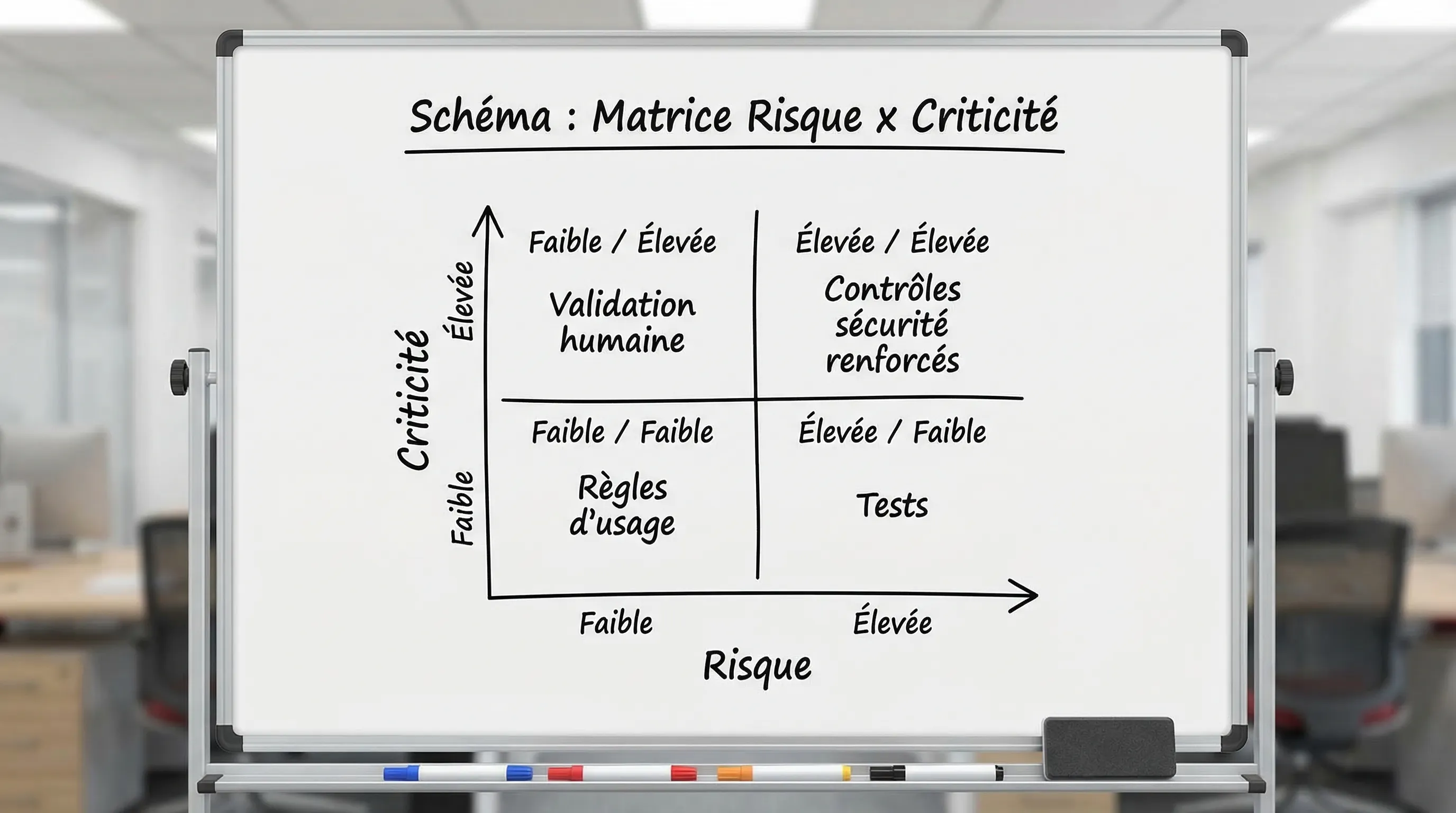
Key risks of artificial intelligence in the enterprise (and the controls that really count)
The risks below cover the majority of incidents observed on AI projects in SME/scale-up environments. The idea is not to treat everything at a "bank" level, but to align the level of control with the level of criticality.
1) Data leakage and confidentiality (the number 1 risk in practice)
Frequent scenarios: an employee pastes a contract into a consumer tool, a support chatbot receives sensitive data, a connector grants too many rights, logs contain PII.
Priority controls:
Data classification (e.g., green, orange, red) and associated usage rules.
Choice of tools and providers with contractual guarantees (DPA, non-reuse clauses, retention).
Minimization: transmit only what is necessary, pseudonymize when possible.
PII filtering on the orchestration side (redaction) and log policies.
Access management (SSO, RBAC, separation of environments).
Useful reference: the CNIL regularly publishes recommendations on the use of generative AI and data protection, to be integrated into an internal policy.
2) Hallucinations, errors, and unverified "truths"
The risk is not that the AI makes a mistake, it's that it makes a mistake with confidence. In cases like support, legal, finance, or compliance, errors can be costly.
Priority controls:
Separate "drafting" use cases (tolerance for approximation) from "truth" cases (requiring sources).
Implement RAG (internal sources) when the AI must answer based on company content.
Require citations or links to a source of truth when possible.
Define refusal rules (fallback): if the confidence level is low, the AI must escalate.
Tests with a set of representative scenarios and a maintained "golden set".
As soon as an AI influences a refusal (credit, HR, pricing, fraud, compliance), you enter a zone where explainability, fairness, and contestability become structural.
Priority controls:
Map "high-impact" decisions and impose a human in the loop.
Measure performance by segments (e.g., customer categories, regions, channels) to detect discrepancies.
Document data, assumptions, limitations, and recourse procedures.
The cost of a POC is often misleading. In production, costs explode via volume, overly long context, latency, observability, RAG maintenance, and adoption.
Priority controls:
Budgets and quotas, alerting, and measures per flow (tokens, latency, error rate).
Caching, summarization, model routing (smaller model when possible).
Load tests and degradation strategy ("safe" mode).
Rapid implementation: a pragmatic 30-day plan (without blocking delivery)
The classic mistake is to wait for "perfect governance" before delivering. Conversely, delivering without control creates debt and, often, a brutal stop. A good compromise is to deliver a V1 that is instrumented and controlled.
Week 1: Scoping and minimal rules
Choose 1 high-frequency use case (e.g., support assistant, internal knowledge, triage).
Define 3 to 5 KPIs, including at least 1 guardrail (quality, risk, cost).
Classify data and define the "red = forbidden" rule (or dedicated pipeline).
Week 2: Controlled MVP
Build a limited version (scope, sources, channels, users).
Implement logs, source traceability, and escalation mechanism.
Write a simple test pack (20 to 50 realistic scenarios).
Week 3: Pilot and measures
Deploy to a restricted group, with structured feedback.
This is precisely the value of an opportunity audit or a strategic AI audit: mapping value and risks, then deciding what to deliver first with the right level of control.
How Impulse Lab supports AI in the enterprise, without vague promises
Impulse Lab generally intervenes on three complementary levers, depending on your maturity:
Opportunity and risk audit: to prioritize measurable use cases and define adapted controls.
Adoption training: to avoid shadow AI and standardize best practices (data, prompts, validation).
Custom development and integration: when ROI depends on integration with your tools, traceability, and an industrializable V1.
If you already have use cases in mind, a good starting point is to formalize a mini-registry (2 pages) with: objective, data, risks, controls, KPIs, and test plan. Then, the challenge becomes simple: deliver fast, measure, and reinforce controls only where necessary.
AI at Work: 10 Tasks to Delegate Without Losing Control
AI at work is useful when it removes friction, not when it replaces business judgment. For SMEs and scale-ups, the right question isn't "what can AI do for me?", but rather: "what tasks can I delegate to it to save time while keeping control?"